Python Lists: A closer look, part 3
MP #5: Understanding comprehensions
Note: The previous post in this series discussed the main reasons that lists become inefficient to work with in some situations. The next post discusses when to use a tuple instead of a list.
I wanted to talk about lists and tuples in this installment, but we really ought to spend a little time on comprehensions first. A working understanding of comprehensions is foundational to using Python well. If you’re not clear yet about what comprehensions are or how they work, it’s worth investing a little time becoming more comfortable with them. If you’ve already started using comprehensions, a deeper understanding of them can help you understand other sequences and collections better.
Discussing comprehensions will bring us quickly to other ideas that I won’t spoil by naming right away. If you already use comprehensions, consider skimming the rest of the post to see if there’s any aspect of this discussion that’s new to you.
What is a comprehension?
I like to start discussions about comprehensions by going back to one of the most basic ways of building a list. We’ll start with an empty list, and add elements one at a time until we have all the elements we need. Here’s a short program that generates a sequence of the first 100 square numbers:
# squares.py
squares = []
for x in range(1, 101):
square = x**2
squares.append(square)
print(squares)This probably looks familiar to you. We start with an empty list, and then define a sequence that we want to build the list from (the range from 1 to 100). Inside the loop we provide an expression that generates each new element, and then append each element to the list. Finally, we print the list to verify it does what we expect it to:
[1, 4, 9, 16, ... ,10000]Now let’s look at a comprehension that builds the same exact list:
# squares_comprehension.py
squares = [x**2 for x in range(1, 101)]
print(squares)One of the mistakes in talking about code is to boldly claim that something is “simpler”. If this code already makes sense to you, or if you understand it intuitively, then you’d easily agree that this is simpler. But if it doesn’t make sense to you (or someone you’re working with), then it’s meaningless to call comprehensions “simpler” than append-based loops.
There is, however, one thing we can all agree on. This code is definitely shorter. More concise coding syntax is beneficial when we understand it, because it leaves us free to focus on other parts of a program. When you’ve worked with comprehensions enough to understand them, they take up much less space in a program than multi-line loops do. This is true both in the sense of physical space on the screen, and mental space as well. Comprehensions, when you understand them, make for less visual and mental clutter in a program.
Inside a comprehension
Let’s dig into this comprehension, and identify its parts. Stripping away as much as we can from the previous program, we’re left with this:
x**2 for x in range(1, 101)There’s really two parts here. I’m going to rearrange the parts, and add some clarifying text:
for x in range(1, 101) generate the value of the expression x**2Hopefully, this is pretty clear. For every value x in the range from 1 to 101, please generate the value of the expression x to the second power. This would be really verbose syntax to have to write, which is part of why we end up with the syntax that actually works.
If we wrap the syntactically correct code in parentheses, we have a valid Python statement:
>>> (x**2 for x in range(1, 101))
<generator object <genexpr> at 0x10b5fa5e0> This is what’s called a generator expression. You can think of a generator expression as a rule for defining a sequence1. A generator expression is an object, like everything else in Python, so you can assign it to a variable:
>>> square_genexpr = (x**2 for x in range(1, 101))Poking at generator expressions
Let’s look at the size of the list we’ve been talking about2:
>>> squares = [x**2 for x in range(1, 101)]
>>> sys.getsizeof(squares)
920A list containing the first 100 square numbers takes up 920 bytes of memory. Let’s look at the size of the generator expression that creates this list:
>>> square_genexpr = (x**2 for x in range(1, 101))
>>> sys.getsizeof(square_genexpr)
104The rule itself only takes up 104 bytes. It takes up less space to store a rule than it does to evaluate the rule over a given range.
You can see this difference even more starkly if you make the comparison using a sequence of a million numbers:
>>> squares = [x**2 for x in range(1_000_000)]
>>> sys.getsizeof(squares)
8448728
>>> square_genexpr = (x**2 for x in range(1_000_000))
>>> sys.getsizeof(square_genexpr)
104The list now takes up much more space (8,448,728 bytes), but the generator expression doesn’t take up any more space. That’s because the rule hasn’t changed.
This is called lazy evaluation. The list is evaluated as soon as it’s defined. The generator expression is not evaluated until we start to use it. It’s been defined, but it hasn’t been evaluated.
Using generator expressions
So, what can you do with a rule? How does a comprehension turn a generator expression into a list? To answer these questions, it’s helpful to keep working in a terminal session.
We’ll start by redefining the generator expression, and assigning it to a variable:
>>> square_genexpr = (x**2 for x in range(1, 5))We’ll use a shorter range, so we can work through the entire sequence.
The built-in function next() returns the next element in a generator expression. Generator expressions track how many times they’ve been asked to return a value, so if you call next() on a newly defined generator expression, you’ll get the first value in the sequence:
>>> next(square_generator)
1You can call next() again, and since the generator is tracking how many times it’s been called, you’ll get the next value:
>>> next(square_generator)
4If you keep doing this until you reach the end of the sequence, you’ll eventually get a StopIteration exception:
>>> next(square_generator)
9
>>> next(square_generator)
16
>>> next(square_generator)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIterationThis is how generator expressions are used to evaluate a sequence. When you ask Python to generate a list from a generator expression, it evaluates each item in the sequence and adds it to a new list, until it receives a StopIteration exception.
If you call next() again after receiving the StopIteration exception, you’ll just receive another exception:
>>> next(square_generator)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIterationCan you reuse a generator expression?
You might be wondering if it’s possible to reuse a generator expression. There’s no way to “reset” a generator expression. If you need to reuse a generator expression, you can redefine it. However, if you find yourself doing this, you should ask yourself if you could simply be using an actual sequence instead of a generator expression.
What are generator expressions used for?
Generator expressions are extremely concise ways to define sequences. In many situations, it’s helpful to be able to define a sequence in one line of code. This is especially true when combining a simple generator expression like we’ve already seen with an if block, which we’ll look at next.
Generator expressions also allow you to define sequences that are too slow or impossible to work with if you tried to build a full sequence and hold it in memory. Here’s a single line of code that generates a list of 20 million items, stored in a .py file so we can easily measure how long it takes to run:
# squares_twenty_million.py
squares = [x**2 for x in range(20_000_000)]This takes about 5 seconds to run:
$ time python3 squares_twenty_million.py
python3 squares_twenty_million.py 5.09s user 0.30s system 97% cpu 5.513 totalNow let’s run a file that contains a generator expression for this same sequence:
# squares_twenty_million_genexpr.py
squares_genexpr = (x**2 for x in range(20_000_000))This takes almost no time at all to run:
$ time python3 squares_twenty_million_genexpr.py
python3 squares_twenty_million_genexpr.py 0.02s user 0.01s system 90% cpu 0.029 totalIt takes 0.02 seconds to parse this expression, which is the same time it takes to run a Hello world program on my system. Since we’re not iterating through the sequence defined by the generator expression, there’s no work to do. This is very different than building a large list and storing it in memory.
This means you can define a generator expression for a sequence that wouldn’t fit in your system’s memory, or one that would slow your system to a crawl. Generator expressions let you work in pieces over sequences that are too large to manage in their entirety on your system. You can work with one item at a time from a long sequence represented by a generator expression, or you can batch your next() calls and work with chunks of the sequence. This allows you to manage the tradeoff between memory and processing speed in a way that works for the particular situation you’re dealing with.
Back to comprehensions
Let’s look one more time at the same comprehension we started with:
squares = [x**2 for x in range(1, 101)]Hopefully this code means more to you now, even if you’ve already started using comprehensions. The square brackets surrounding the generator expression tell Python to evaluate every item in the sequence, and return a list filled with those values.
Comprehensions are faster than append loops
One of the main reasons for preferring comprehensions is how concise they are. But, they’re also more efficient. Let’s build 20 million squares by appending in a loop, with a temporary variable to define each new element:
# squares_twenty_million_append_tempvar.py
squares = []
for x in range(20_000_000):
square = x**2
squares.append(square)This takes about 6.7 seconds on my system.
Before comparing this to a comprehension, let’s remove the temporary variable and see if there’s a difference:
# squares_twenty_million_append.py
squares = []
for x in range(20_000_000):
squares.append(x**2)This takes about 6.1 seconds, for a roughly 9% speedup. This doesn’t mean you should never use a temporary variable in a loop; there’s a balance between speed and readability. If there’s a complex rule or process for defining each value, it can be beneficial to use a temporary variable. In some cases you’ll need multiple lines to define each element before calling append().
Now let’s compare the append loop to a comprehension:
# squares_twenty_million.py
squares = [x**2 for x in range(20_000_000)]This takes about 5.1 seconds on my system. That’s a speedup of about 16% over the append loop without the temporary variable, and about 24% over the loop that used a temporary variable.
As always, this informal measurement warrants a caveat. We’re not actually doing anything with these lists, and they’re simple examples with simple rules for generating each element. When you run into code that’s starting to run slow, accurately profiling your specific codebase is critical in choosing which optimizations to implement. That said, the principles you’ve seen here apply pretty generally in the Python world.
Conditional expressions in comprehensions
You can include a conditional expression at the end of a generator expression, to select certain elements from a sequence. For example, here’s a generator expression that produces even numbers:
(x for x in range(100) if x%2 == 0)If you haven’t seen the % operator before, it’s called the modulo operator. It checks the remainder after dividing x by 2. If that remainder is 0, the number must have been even.
Where this really shines is pulling out items that meet certain conditions from a list. Let’s say you’re running an online store, and you have a list called orders. This is a mix of orders that have shipped, and orders that haven’t yet shipped. You want to check on all the orders that haven’t shipped yet, so you decide to make a list containing only those orders. Here’s a block of code showing how you might build that list with a loop:
unshipped_orders = []
for order in all_orders:
if not order.shipped:
unshipped_orders.append(order)This works, but it’s four lines of code with three levels of indentation. You can generate this same list in one line using a comprehension:
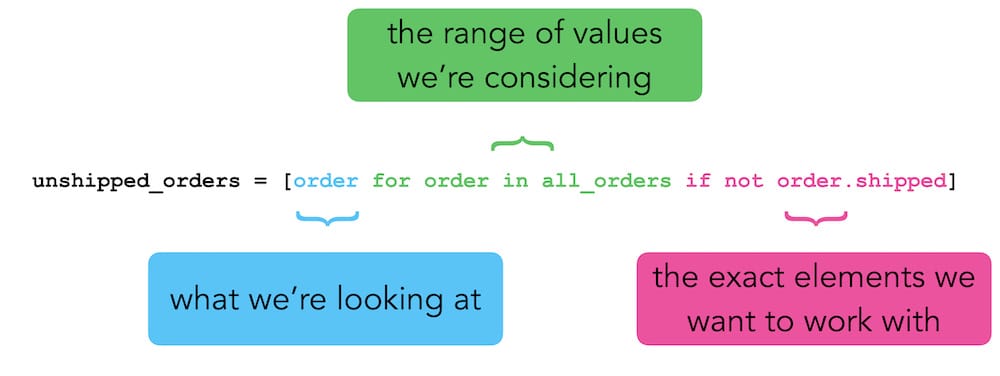
unshipped_orders = [order for order in all_orders if not order.shipped]This is extremely efficient syntax once you’re comfortable reading and writing comprehensions. If you’re not quite there yet, it might help to see this in three parts. First, we’re working with an order:
unshipped_orders = [order for order in all_orders if not order.shipped]Where does each order come from? We’re looking at every order in the list all_orders:
unshipped_orders = [order for order in all_orders if not order.shipped]And which orders are we interested in? We’re interested in the ones where the value of order.shipped is False:
unshipped_orders = [order for order in all_orders if not order.shipped]Comprehensions have a reputation for being difficult for people who are just learning Python. One reason for this is that comprehensions can be represented by fairly long statements. However, if you can learn to look at them in parts like this, you can probably start to work with them more comfortably.
Here’s a visual representation of this way of looking at comprehensions:
A word of caution
Some people learn about comprehensions, and then try to implement every list they ever use as a comprehension. However, because you can nest comprehensions, and have complex conditional rules at the end of each comprehension, this approach doesn’t always result in readable code. If the one programmer on a team who’s become a comprehension guru writes code that no one else on the team can make sense of, then that list would probably be better implemented using a slower, but more readable append loop.
As always, writing code in real world projects means balancing performance and readability for the people you’re actually working with.
Conclusions
List comprehensions are often taught as simply being “shorter ways of generating lists”. But there’s a lot more going on than just generating a list in fewer lines of code. If you take the time to really understand what’s happening when Python builds a list defined by a comprehension, you’ll be on your way to a deeper understanding of the language as a whole.
Concise syntax also allows the language to implement a more efficient approach to building a list than what’s possible when evaluating an explicit append loop. Comprehensions are more performant than append loops, and you should use them unless you have a specific reason not to.
Conditional statements in comprehensions are perfectly reasonable, and you should use them as well. If you start to nest comprehensions, or the conditional statements in the comprehensions are complex, consider going back to an append loop. There’s great value in writing code that’s easy to understand. This helps others you might be collaborating with, and it also helps you when you come back to your own code after working on something else for a while. If you have a good reason to use a complex list comprehension, consider running it through a code formatter so it’s broken up well. Also, write clear comments about how it works, and why it should be implemented as a comprehension.
What’s next
This detour through comprehensions and generator expressions will serve us well in the rest of the discussions in this series. For example, the next post will compare lists and tuples. When we look at tuples, we’ll use generator expressions to make more interesting examples.
Resources
You can find the code files from this post in the mostly_python GitHub repository.
There are several parts of the Python documentation that are worth looking at if you’re interested in following up on anything that was brought up here.
Sequence Types — list, tuple, range
This is a helpful overview of all the basic sequence types in Python.
Data Structures: More on Lists
This is a more focused discussion of lists.
This is part of the “More on Lists” section, which focuses on list comprehensions.
As mentioned in a footnote, there’s a lot of specific terminology that’s thrown around in these discussions. If you’re ever unsure exactly what a term refers to, this is a great place to look.
Further exploration
If you’re curious to explore this a little further through code, it’s an interesting exercise to write your own get_list() function.
get_list
Write a function called get_list(), that takes in a generator expression and returns a list. Verify that your function actually returns a list. Once you’re confident that your function does what it’s supposed to, use it to evaluate a large sequence. How does the performance of your function compare to simply using a comprehension3?
Note: Don't cheat and call list(generator_expression) in your function! Use the next() function on the generator that's passed to your function.
Note that we’ll keep using the phrase generator expression throughout this post. Python has an excellent glossary, and you’ll find entries for generator, generator iterator, and generator expression. Distinguishing between these is a full discussion in itself, so we won’t get into the differences between each of these at this point. ↩
I’ve already run
import sysin this terminal session. If you’re running this code yourself, remember to make thatimportcall. ↩Your function will almost certainly be slower than simply using a comprehension. If your implementation is faster, please let us all know! Python’s implementation has been heavily optimized, so a performance comparison is not particularly meaningful unless you want to get into lower level implementation details. However, it does give you a better idea of what’s happening behind the scenes with a lot of Python code. ↩



