Why we have third-party ecosystems

MP 122: And why I like them so much.
Something people new to Python don't always understand well is the role of "third party" packages in the ecosystem. People learn the basics of Python, and then they want to do something that requires functionality that's not covered by the core language or the standard library. They then discover all the packages on PyPI, and it's a great moment as a new developer. There's so much functionality just a pip install away!
But after installing a package like httpx to fetch online data, or black to format their code, people start to ask why that functionality isn't just included in Python by default. It's a natural question to ask; if code has been written to make fetching online data easier, why isn't that code just included in Python itself? Why do you have to install Python, and then install all these libraries after the fact?
I imagine there's also plenty of people who've grown accustomed to using a variety of third-party packages, without fully understanding why they have to go through this process as well. In this post I'll share some of the reasoning behind the existence of third-party ecosystems, and why I like it both as a user and a maintainer of third-party packages.
Python's core and the standard library
It's helpful to understand two specific aspects of Python, the core of the language and the standard library. The "core" is anything you can use without writing an import statement. For example, you can use the input() function without importing anything:
$ python >>> name = input("Who are you? ") Who are you? Eric >>> name 'Eric'
The resources needed for the most essential aspects of loading, manipulating, and storing data are in the core part of the language.
The standard library includes functionality that's used commonly across many disciplines. Resources from the standard library need to be explicitly imported before they can be used:
>>> from random import randint >>> die_roll = randint(1,6) >>> die_roll 3
The core of Python is loaded into memory every time you run a Python program, no matter how simple or complex it is. The standard library is available, but it's not loaded. This makes programs much more efficient than if everything was loaded all the time.
On my system, here's the location of a Python 3.12 interpreter:
>>> import sys >>> sys.executable '/Users/eric/.pyenv/versions/3.12.2/bin/python'
With a file browser, I can see that the python executable takes up less than 35KB of space:
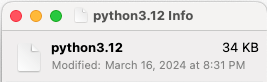
Note that the python executable is a single file, not a directory.
You can find the path to the standard library as well:
>>> import sysconfig >>> sysconfig.get_path("stdlib") '/Users/eric/.pyenv/versions/3.12.2/lib/python3.12'
If I look at this directory in a file browser, I can see that it's much larger:
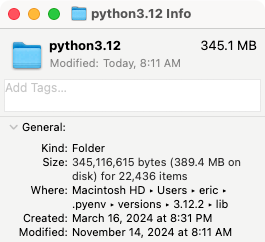
The standard library is a folder, not just a single file. This screenshot shows that it takes up about 345MB on my system, spread across 22,000 files and folders. The actual size is smaller than that, because this isn't a fresh install and some caches are included here. But the point remains, that the standard library is much larger than the core footprint of Python.
As always, I encourage you to poke around in these files and directories. If you find this folder on your system and look inside, you can see that random from the import random statement is just a single file called random.py. You can look in there, and see that randint() is just a single-line function wrapping randrange():
def randint(self, a, b): """Return random integer in range [a, b], including both end points. """ return self.randrange(a, b+1)
In contrast, something like json is actually a folder with several .py files handling different aspects of working with JSON data.
The Python software ecosystem
It might be helpful to see a visualization of the Python ecosystem. Here's a representation of several aspects of the Python software world:
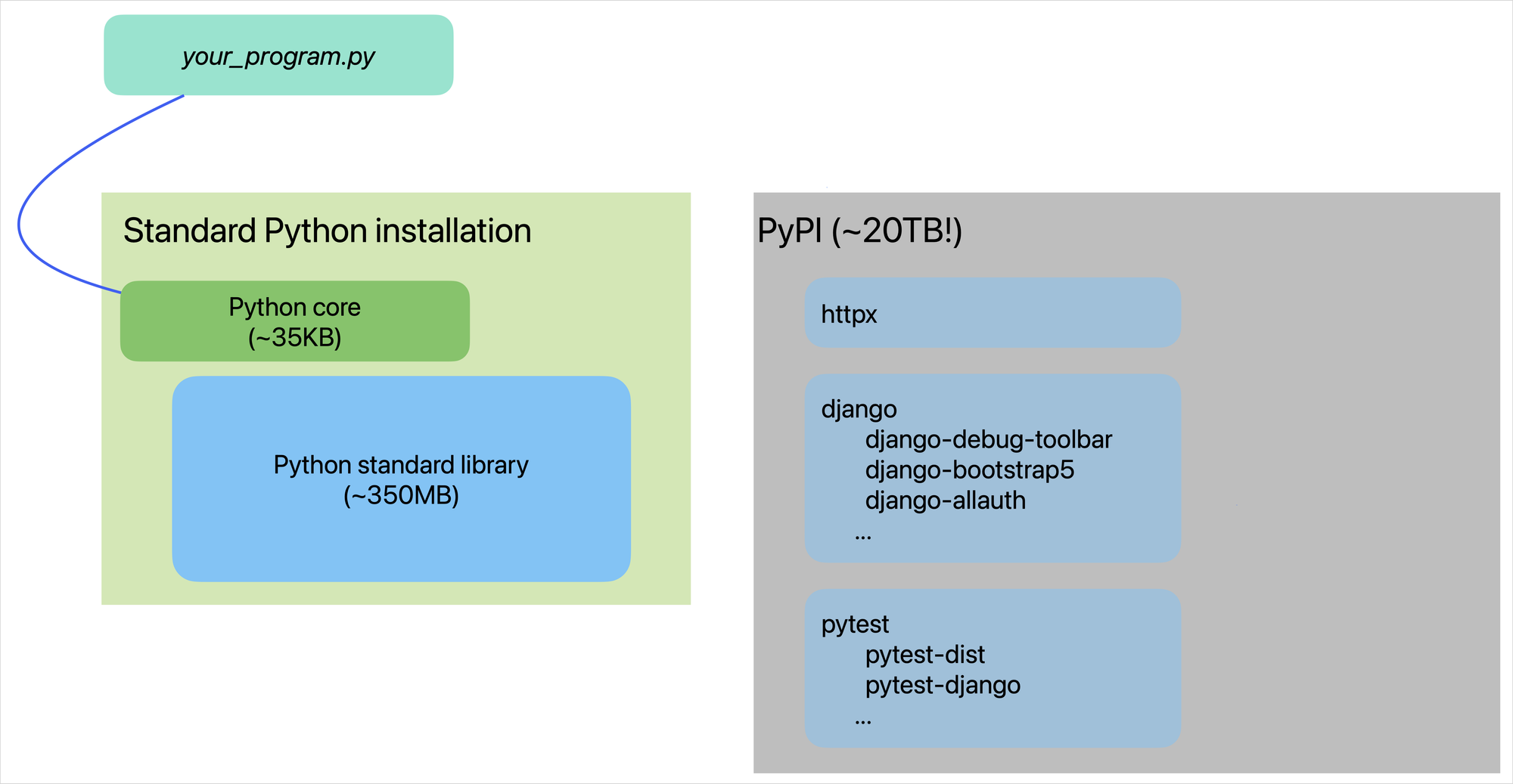
Every Python program you write uses Python's core when it runs. But you have to choose what to include beyond that. If the entire standard library was all included all the time, every program would be hundreds of megabytes. That would really add up!
The layering of the Python world becomes even clearer when you look at PyPI. If you want to download all the packages on PyPI, you'd need over 20TB of storage! When you take all this into account, you can start to understand why we need layers of packages in the Python world, and can't include everything in the language itself.
Why would someone want their project in the standard library?
Sometimes people have an idea for a new piece of functionality, and they start writing code that implements that functionality. Then they have the idea that it should be part of the language, so it's available to everyone who uses Python.
Sometimes the motivation for this is altruistic; people have addressed a need, and they want the resource they've created to be available to everyone else. But sometimes the desire for a project to be included seems to be a shortcut for getting users. Dumping a new project into the core of the language is not a reasonable way to find users!
Update timelines
One of the clearest reasons new projects should start out as a third-party package is the timeline for pushing updates. If you're writing a new package, you need to be free to push a new release of your library any time you add a new feature or fix a bug. Libraries that are just seeing their first users often see frequent updates, as the use cases get refined and the functional boundaries become more solidly defined.
Many libraries need frequent updates as long as the project is in existence. For example, a library that interacts with an external resource such as a data stream will need to be updated any time the format of that data changes. Maintainers of these kinds of libraries need to remain free to push new releases whenever those external resources change. There are many heavily-used libraries that remain outside the standard library for exactly this reason.
Once a package is included in the standard library, the only way to update it is to push a new release of the entire language. That's a pretty high barrier, so libraries need to be extremely stable and well-tested before they can really be a candidate for inclusion in the standard library. It's perfectly reasonable for most packages to stay outside the standard library for their entire lifetime.
Stability and reliability
A programming language with a large user base must be both stable and reliable. At any moment, Python is being downloaded and installed in all kinds of environments: on people's personal machines, on remote servers, on automated deployments and automated test runs.
Code that becomes part of Python's core, or the standard library, needs to go through intensive testing and validation before it's released. When new code is introduced to the language and makes it into a release version of Python, it's immediately installed to millions of computers all over the world. The Python release process is comprised of a series of automated tests and pre-releases before making it into a final official release. Even with this careful process, bugs do make it into final releases. Minor Python versions fix these bugs, but it's a lot of work to create a new minor release. Python 3.8, which just reached end of life after five years, saw just 20 minor releases to address bugs that were significant enough to warrant a fix in an already-released version of the language.
There are many libraries that are incredibly useful, but haven't been tested enough or seen enough real-world usage to be considered for inclusion in Python's core or the standard library.
Maintenance burden
Another thing to consider is the maintenance burden of anything that's included in the standard library. Once a package is included, it has to be maintained by Python's core developer team. Python has a few paid developers, but most of the work is done by volunteers, or people whose employers are willing to sponsor their time.
Whenever a package is considered for inclusion in the standard library, Python's core developers need to decide whether they feel they can handle the additional workload of maintaining that library. Sometimes there's enough benefit to enough Python users that it's worth including. But more often, it's just not feasible to have a library maintained by core developers.
What belongs in the standard library?
So what does belong in the standard library? If a library is useful to a significant percentage of Python users, is highly stable, has seen widespread usage and doesn't need frequent updates, and it can be reasonably maintained by Python's core developers, it may be a candidate for inclusion in the Python language or standard library.
A good example of this is pathlib. This module started out as a third-party package. PEP 428 proposed including it in the standard library, and the community agreed that it was appropriate to incorporate pathlib into the language itself. It's one of my favorite modules, and I think that was an excellent decision. That said, if it had remained a third-party package, I'd have no issues installing it into each of my projects that uses it.
Deprecation costs
One of the issues developers of new libraries sometimes don't think about is the cost of deprecating the library when it's reached end of life. Programmers don't like to think of their projects becoming useless at some point, but Python's core developers absolutely have to think about this.
A good example of this is a library for handling XML data. XML was a common format in the mid 2000s, and it made as much sense to include an XML library back then as it does to include a JSON library today. But while many of us have moved on from XML and will never touch it again, Python's core developers still have to think about it because it's in the standard library.
When a module is slated for deprecation, it's a process that takes several releases. That's a multi-year process, which core developers need to manage.
Conclusions
As a developer, I really like using third-party libraries. They address an incredible variety of use cases across all kinds of domains. You have to be careful when choosing libraries, because people can put malicious code into these libraries at times. But there are many well-established, well-vetted packages you can choose from. And many more are small enough that you can look through the codebase yourself before deciding whether to incorporate them into your projects.
As a developer, I also appreciate the opportunity to build and help maintain third-party packages. You don't get instant usage by putting a package on PyPI, but you do get access to a reliable and well-known distribution system. It's your responsibility to develop useful, reliable software, and you have to find people who want to use what you're offering. But if you're willing to do those things, the infrastructure is there for you to take advantage of. I especially appreciate the opportunity to develop libraries as quickly or as slowly as I need.
Library maintainers often struggle with discoverability. When there's a good library out there, how do you let people know about it? That's a question for a separate post, but I'll note here that it's also our responsibility as developers to look for packages that would make our work easier. We take for granted that as a Python developer you have to learn about things like lists and dictionaries. But I would argue it's just as important to spend time looking through the standard library, and looking at what's available on PyPI as well. Don't stop when you find a primary package either. Many times there are additional packages that extend the functionality of the main packages you use.
If you feel like sharing, what's your favorite standard library module? What's your favorite third-party package?



