Python Lists: A closer look, part 6
MP #12: When to consider using arrays
Note: The previous post in this series showed how to profile your code, so you can identify bottlenecks. The next post discusses when it’s appropriate to use sets instead of lists.
In this post we’ll look at NumPy arrays. In many situations, working with arrays can be much more efficient than working with lists. The tradeoff for this efficiency is an increase in complexity. Working with arrays requires more specialized knowledge, and results in less readable code. However, even if you don’t develop a full understanding of how to use arrays right away, knowing they’re an option will help you recognize when they might be relevant to your work.
Arrays tend to be useful when working with large datasets, and when doing a lot of processing on smaller datasets. For this example we’ll focus on a small dataset—just 3,000 elements—but we’ll do so much processing that the work will start to slow down significantly with lists.
Keep in mind that you don’t have to understand all of the code in this example in order to follow the main point about arrays. Feel free to skim through the discussion of the coin-flipping example, and focus on the section Why try arrays? Notice how arrays are used in the final version of the program, and what impact they have on the program’s performance.
Flipping coins
We need a small dataset involving just one kind of data, which we can do many operations on. So let’s look at flipping coins. Coin flipping is a good context to work with because there are lots of interesting questions we can ask about the results of a sequence, and many ways you can explore different solutions with code. There are mathematical approaches to answering many of these questions, but you can often arrive at the same results through code, even without a strong mathematical background.
Consider a sequence of 1,000 coin flips:
['H', 'T', 'T', 'H', 'T', 'T', 'H', 'H', 'T', ..., 'H']We’ll focus on the following question:
In a sequence of 1,000 coin flips, what run of at least 100 flips has the highest percentage of heads?
Think about that question for a moment, and consider what you think the answer might be. If you want, try to write a program that answers this question before reading any further.
Generating data
If you haven’t used it before, the random.choice() function returns a random element from a sequence. The following code generates a single random coin flip:
>>> import random
>>> outcomes = ('H', 'T')
>>> random.choice(outcomes)
'H'The choices() function is more useful in the problem we’re working on, because it lets you specify how many random choices to return:
>>> random.choices(outcomes, k=10)
['H', 'H', 'T', 'T', 'H', 'T', 'H', 'H', 'T', 'H']With that, here’s a program that generates a random sequence of coin flips:
# best_sequence.py
import random
def get_flips(num_flips=10):
"""Return a random sequence of coin flips."""
outcomes = ('H', 'T')
return random.choices(outcomes, k=num_flips)
# Generate flips.
all_flips = get_flips()
print(f"Generated {len(all_flips):,} flips.")
print(all_flips)We have a function called get_flips(), to keep the overall program organized and readable.
In exploratory code like this, I almost always insert summary print() calls, so I know the code is generating the kind and amount of data I think it is. During the development process, while working with a smaller dataset, I like to print the data as well. If the full dataset is too long to print, you can always print just a slice of the data, such as the first few items in all_flips.
Here’s the output:
Generated 10 flips.
['H', 'T', 'T', 'T', 'T', 'T', 'H', 'T', 'H', 'H']We have a small dataset to start with, and the outcome looks random. Running the program several times shows different sequences of flips as well.
A simpler question
I was a math teacher for many years, and one of my favorite problem-solving strategies to share with students was starting with a simpler version of the problem you actually want to solve. It might be hard to visualize a solution that works with 100-flip sequences, so let’s answer a simpler version of the question first. This strategy works especially well in programming. If you choose the right parameters, you can adjust the values in your solution code, and your program will often work on the original problem as well.
Here’s a simpler version of the question we started with:
In a sequence of 10 coin flips, what run of at least 4 flips has the highest percentage of heads?
This is a small enough amount of data to work with that we can develop a solution and verify that it works. Then we can apply that same solution to the original question.
A visual solution
Making sketches is really helpful in solving problems. Simple rough sketches carried me through many math and science classes, helped me figure out many house projects, and have often been effective in programming work as well. Let’s try it for this problem.
We’re looking for sequences of four flips or more, and we want to start at the beginning of the sequence. So we’ll look at the first 4 elements, the first 5 elements, the first 6 elements, and so on until we’ve reached the end of the list. Here’s a nicer version of the sketch I drew for this problem:
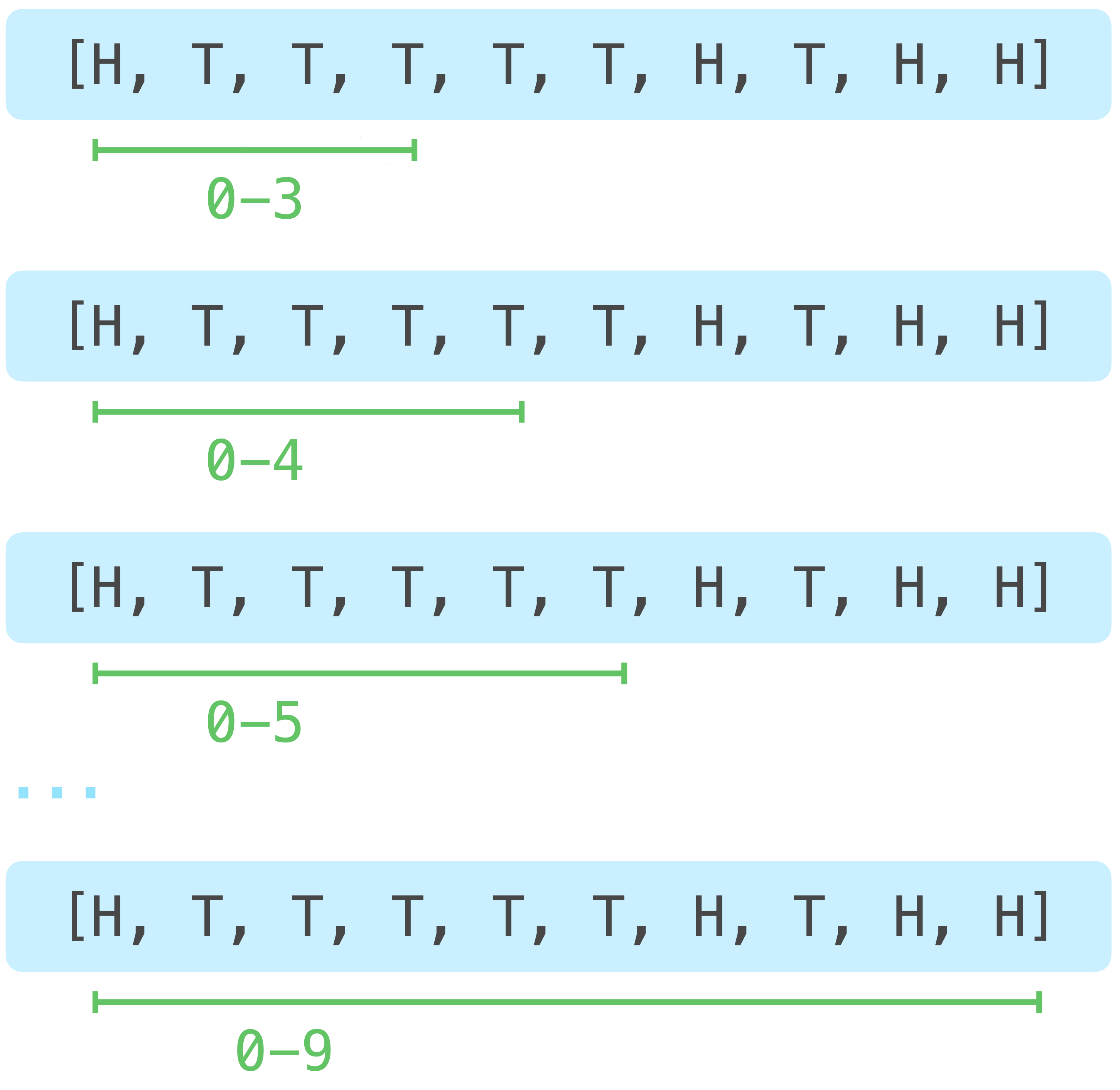
The numbers shown correspond to the indexes of each item in the sequence. If we examine each of these sequences, we’ll look at all possible runs starting with the first flip, which include at least 4 flips. We’ll then examine a similar set of runs starting with the second flip:
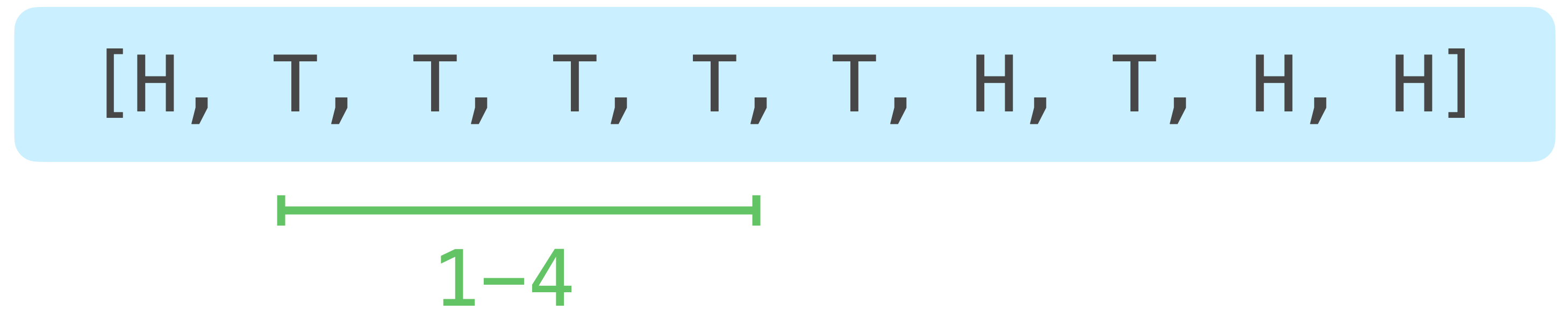
Each of these “runs” is going to be represented by a slice in our code. Here’s the last run we’ll examine:
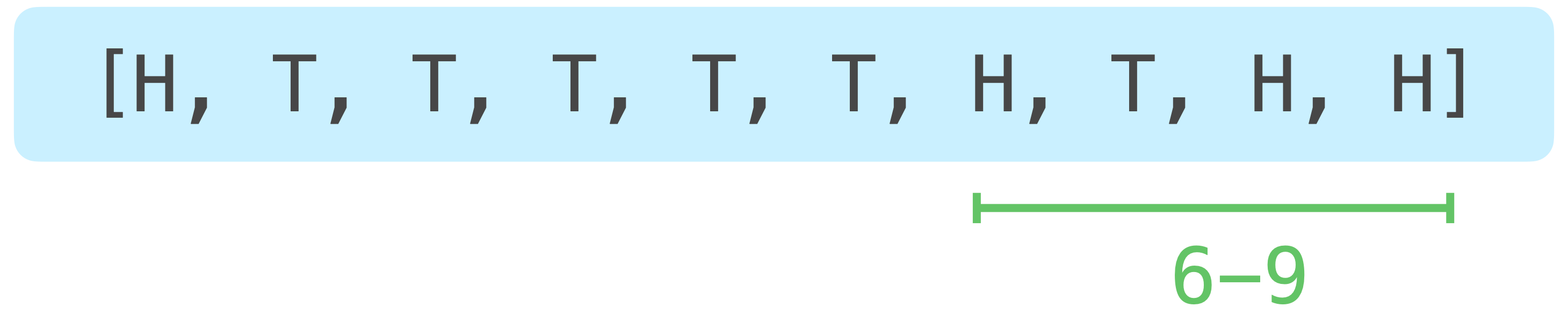
The runs we’re interested in need to have at least 4 elements, so the last run spans elements 6 through 9. A run starting at element 7 would be too short, so we never have to examine it.
The important thing to notice here is what indexes we’ll use for the beginning of each run, and what indexes we’ll use for the end of each run. The starting indexes go from 0 through 6. If we call the minimum run size threshold, the final starting index will look something like len(all_flips) - threshold. In this kind of work, I always keep in mind I might be making an off by one error, until I prove to myself that I’m working with the correct slices.
The ending indexes go from 3 through 9, but a full expression for the ending index on each pass through the loop will depend on the current starting index.
Turning this into code
Here’s a function that implements this solution:
def get_best_sequence(flips, threshold):
"""Find the sequence with the highest percentage
of heads, with a length above the threshold.
Returns:
- Sequence with highest heads percentage.
- Percentage heads for that sequence.
"""
best_percentage = -1.0
# Loop over all slices above the threshold size.
for start_index in range(len(flips)-threshold+1):
for end_index in range(start_index+threshold, len(flips)+1):
current_slice = flips[start_index:end_index]
percent_heads = current_slice.count("H") / len(current_slice)
print(f"{start_index}:{end_index-1} {current_slice}")
# If this is the best sequence, store it.
if percent_heads > best_percentage:
best_percentage = percent_heads
best_sequence = current_slice
return best_sequence, best_percentage*100This function needs two pieces of information: a sequence of coin flips to act on, and the threshold for how long each run needs to be. It returns two pieces of information: the sequence with the highest percentage of heads, and the percentage heads for that sequence.
The most complicated parts of this code are the two lines that set the values for start_index and end_index for each slice that needs to be examined. The values for start_index correspond to what’s shown in the visualizations above:
for start_index in range(len(flips)-threshold+1):Remember that range() with a single argument returns a sequence beginning at 0. So the starting index for each slice will go from 0 to the number of flips in the entire dataset, minus the threshold. The +1 is included because range() stops at one less than the argument value, because a slice includes the starting index.
The values for end_index depend on the current value of start_index. Whatever start_index is, the lowest end value is start_index plus the threshold length. The last end value is the last item in the list, which we get from len(flips). We need to add one here as well, because range() doesn’t return the last value in the range.
for end_index in range(start_index+threshold, len(flips)+1):There’s also one diagnostic print() call in this function, so we can verify that we’re looking at the correct slices on our initial small dataset. We’ll remove this line before running the code against a larger dataset:
print(f"{start_index}:{end_index-1} {current_slice}")On every pass through the nested loops we’ll see the bounds of the current slice, and all of the flips in that slice.
If this function doesn’t completely make sense, don’t worry. The point is that we’re passing a list of coin flip results to get_best_sequence(), and it’s iterating over a bunch of slices of that list to find the slice with the highest percentage of heads.
Running the analysis
Here’s the entire program:
# best_sequence_verbose.py
import random
def get_flips(num_flips=10):
...
def get_best_sequence(flips, threshold):
...
# Generate flips.
all_flips = get_flips()
print(f"Generated {len(all_flips):,} flips.")
print(all_flips)
# Find best sequence.
print("\nAnalyzing flips...")
best_sequence, percentage = get_best_sequence(all_flips, threshold=4)
print(f"\nThe best sequence has {len(best_sequence):,} flips in it.")
print(f"It consists of {percentage:.1f}% heads.")
print(f"Best sequence: {best_sequence}")We call get_best_sequence(), and print some summary information. Here’s the output for 10 coin flips with a threshold of 4 flips:
$ python best_sequence_verbose.py
Generated 10 flips.
['T', 'T', 'H', 'H', 'T', 'H', 'T', 'H', 'T', 'H']
Analyzing flips...
0:3 ['T', 'T', 'H', 'H']
0:4 ['T', 'T', 'H', 'H', 'T']
0:5 ['T', 'T', 'H', 'H', 'T', 'H']
...
0:9 ['T', 'T', 'H', 'H', 'T', 'H', 'T', 'H', 'T', 'H']
1:4 ['T', 'H', 'H', 'T']
...
1:9 ['T', 'H', 'H', 'T', 'H', 'T', 'H', 'T', 'H']
2:5 ['H', 'H', 'T', 'H']
...
6:9 ['T', 'H', 'T', 'H']
The best sequence has 4 flips in it.
It consists of 75.0% heads.
Best sequence: ['H', 'H', 'T', 'H']I’ve omitted some of the output, but you can see that it examines all of the slices that we discussed above. The slice 0:9 looks at the full sequence of flips, and the last sequence examined is indeed the last 4 flips in the entire dataset. Every other possible sequence above the threshold length is included in the output.
Answering the original question
Now we can set the arguments num_flips to 1_000 and threshold to 100, and answer the original question. (I also eliminated the diagnostic print() calls, while keeping the summary output.)
$ time python best_sequence_1k.py
Generated 1,000 flips.
Analyzing flips...
The best sequence has 107 flips in it.
It consists of 61.7% heads.
python best_sequence_3k.py 1.66s user...In this run, the best sequence consisted of 61.7% heads. This took just over 1.6 seconds, which is fine if this is as far as you need to go.
A larger dataset
Let’s increase the number of flips until the program slows down noticeably. It doesn’t take much, because the number of slices that need to be examined grows quickly. Here’s the output for examining 3,000 flips, while keeping the threshold at 100:
$ time python best_sequence_3k.py
Generated 3,000 flips.
Analyzing flips...
The best sequence has 103 flips in it.
It consists of 66.0% heads.
python best_sequence_3k.py 48.25s user...The percentage this time is 66.0% heads, but it took 48 seconds to run. Let’s profile this, and see where it’s spending all that time.
Profiling
Here’s the results of profiling this code with 3,000 flips and a threshold of 100:
$ python -m cProfile -s cumtime best_sequence_3k.py
Generated 3,000 flips.
Analyzing flips...
The best sequence has 100 flips in it.
It consists of 67.0% heads.
8429046 function calls (8429014 primitive calls) in 51.607 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
3/1 0.000 0.000 51.607 51.607 {built-in method builtins.exec}
1 0.000 0.000 51.607 51.607 best_...3k.py:1(<module>)
1 9.925 9.925 51.601 51.601 best_...3k.py:8(get_best_sequence)
4209351 41.275 0.000 41.275 0.000 {method 'count' of 'list' objects}
4212264 0.401 0.000 0.401 0.000 {built-in method builtins.len}
...The program is spending almost all its time running the count() method. Even for a small dataset of 3,000 coin flips, count() is called over 4 million times!
Let’s try using an array instead of a list, and see how this performance changes.
Why try arrays?
Arrays have two restrictions that lists do not:
Arrays have a fixed length.
Arrays should only contain data of one type.1
These are simple restrictions. But if the sequence you’re working with meets these requirements, many operations can be highly optimized. Rather than inspecting every element, array methods can identify the kind of information in the entire sequence, and then repeat the same operation many times. Because arrays have a fixed length, they use memory more efficiently as well.
I’ll save a full discussion of how to define arrays for a later post.2 For now we’ll take the list all_flips and convert it to a NumPy array. Add the following import statement at the top of the file:3
import numpy as npNow convert all_flips to an array before passing it to get_best_sequence():
# best_sequence_3k_array.py
...
# Generate flips.
all_flips = get_flips(num_flips=3_000)
all_flips = np.array(all_flips)
print(f"Generated {len(all_flips):,} flips.")If you run the file at this point, you’ll get the following error message:
'numpy.ndarray' object has no attribute 'count'Some array-based operations, such as slicing, have syntax that matches the equivalent operation for lists. Some operations are done differently on arrays. Arrays don’t have a count() method, but a little research shows a variety of options. Here’s a pretty interesting approach:
>>> import numpy as np
>>> flips = np.array(['T', 'T', 'H', 'H', 'T'])
>>> flips == 'H'
array([False, False, True, True, False])If you compare an array to a value with the == operator, you’ll get a new array showing which elements matched that value. Calling sum() on this comparison gives you a count of the values that matched, because each True value is equivalent to 1 in the summing operation:
>>> (flips == 'H').sum()
2Here’s how to use this in get_best_sequence():
# best_sequence_3k_array.py
def get_best_sequence(flips, threshold):
...
# Loop over all slices above the threshold size.
for start_index in range(len(flips)-threshold+1):
for end_index in range(start_index+threshold, len(flips)+1):
current_slice = flips[start_index:end_index]
num_heads = (current_slice == 'H').sum()
percent_heads = num_heads / len(current_slice)
...We get the number of heads in the current slice by comparing the current_slice array to 'H' and then calling sum(). We then divide that result by the number of flips in the slice.
These are all the changes needed to make the program run again, and it runs in half the time:
$ time python best_sequence_3k_array.py
Generated 3,000 flips.
Analyzing flips...
The best sequence has 107 flips in it.
It consists of 64.5% heads.
python best_sequence_3k_array.py 24.03s user...This isn’t blazingly fast, but it’s a significant speedup over the list-based approach. Let’s profile this, to see exactly what’s changed.
Profiling the array solution
Here’s the output of profiling the array-based solution:
$ python -m cProfile -s cumtime best_sequence_3k_array.py
Generated 3,000 flips.
Analyzing flips...
The best sequence has 101 flips in it.
It consists of 63.4% heads.
16913554 function calls (16911770 primitive calls) in 30.157 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
107/1 0.001 0.000 30.157 30.157 {built-in method builtins.exec}
1 0.000 0.000 30.157 30.157 best...array.py:1(<module>)
1 16.676 16.676 30.039 30.039 best...array.py:10(get_best_sequence)
4209352 1.686 0.000 12.885 0.000 {method 'sum' of 'numpy.ndarray' objects}
4209352 1.394 0.000 11.199 0.000 _methods.py:47(_sum)
4209352 9.806 0.000 9.806 0.000 {method 'reduce' of 'numpy.ufunc' objects}
4215779/4215709 0.478 0.000 0.478 0.000 {built-in method builtins.len}
13 0.001 0.000 0.244 0.019 __init__.py:1(<module>)
...More calls are taking place, but they’re more efficient so the overall execution time is faster.
Larger datasets
The larger the dataset, the more impact using arrays has in this solution. For 4,000 flips and a threshold of 100, the list-based approach takes about 121 seconds, while the array-based solution takes 50 seconds.
For 3,000 flips the array-based solution takes 50% of the time that the list-based solution takes; with 4,000 flips that drops to about 40%. This trend would continue as you examine longer sequences of flips.
Conclusions
Arrays aren’t a magic fix for every list-based program that starts to run slowly. For some programs and datasets, using arrays will actually cause your program to run slower. When programs start to become inefficient, the best response to the question How do I get my program to run efficiently? is almost always It depends. In many cases, especially with larger datasets or when there are many repeated operations, trying to use arrays in place of lists is a worthwhile exploration. Whatever you try, make sure you’re profiling your code so you know whether your optimization efforts are targeting the actual bottlenecks in your code.
Using arrays almost always introduces additional complexity. The code for calculating the percentage of heads in each slice using arrays was definitely more complicated than the list-based code. Don’t give up readability to use a “more efficient” data structure if it doesn’t have any meaningful impact on your program’s performance. Once you’re familiar with arrays, you should still use lists whenever they work well enough. Even if you become a NumPy expert, it’s still beneficial to write code that’s easily understood by other people with less expertise.
Finally, I want to point out that there are many optimizations that could be made in this example without resorting to arrays. For example, I believe if you convert the H and T values to 1 and 0, you can come up with a variety of other approaches that would run faster than the initial approach shown here. But you’d have to convert back to H and T in any output that end users see, and you’d still have an algorithm that looks at an increasingly large number of slices.
Resources
You can find the code files from this post in the mostly_python GitHub repository.
Further exploration
1. Original problem
Without looking back at the code in this post, write a program that answers the question we started with: In a sequence of 1,000 coin flips, what run of at least 100 flips has the highest percentage of heads?
2. Thinking mathematically
Using the visualizations shown at the start of this post, calculate how many iterations the loop should make for 10 flips with a threshold of 4. Does that match what the code does? How about 3,000 flips with a threshold of 100?
3. Other optimizations
There are many approaches to consider that might answer the original question more efficiently, while still being able to adjust the values for num_flips and threshold. Think of a different approach than what’s shown here, and use profiling to compare the impact of your optimization efforts.
An array can contain data of different types, but you should almost never do this. Doing so slows down performance to the point where you likely won’t gain any benefit from using an array. You’d probably see similar performance, and have more readable code, by just using a list or another standard Python data structure. ↩
If you’re curious to read more about NumPy, the home page for the documentation is here. The most relevant page to follow up from this post is probably Array creation from the NumPy user guide. ↩
NumPy is included in a number of other packages that you may already have installed. If NumPy is not already installed on your system you can install it with the command
python -m pip install numpy, or a similar command that works on your system. ↩