Building a checklist of all functions in a file

MP 126: How do you make a GitHub task list for reviewing all functions in a file?
I've been steadily working on bringing django-simple-deploy to a 1.0 release, and this has involved a lot of refactoring. At some stages of development, I want to do a quick review of all the functions and methods in a file. When I'm refactoring a short file, it's easy to keep track of all the changes, and I can do it all in one session. But with a longer file it can be much harder to keep track of my progress in reviewing each function.
I ended up writing a small script to parse a program file, and generate a block of markdown that can be pasted into a GitHub issue as a checklist. This makes it much easier to see how much work is in front of me, and track my progress as I review each part of the file. It also makes it easier to pick up the work if I have to step away from it for a bit in the middle of the refactoring process.
In this post I'll walk through the process of writing this script, which involves a brief exploration of regular expressions. In the process of writing about this work, I came up with a much simpler approach than my first take on the problem. I'll close out the post with that simpler version of the program, which you can run against your own .py files.
Parsing a code file
The first thing we need to do is read in the target .py file, and find all the function names. I'm going to use a 500+ line file called deploy.py as an example target file. If you're following along, you can use this or any .py file as a target. (The target file doesn't need to be able to run in your current environment, because we're just parsing it without executing the file.)
Let's first read the file in as a list of lines:
from pathlib import Path path = Path(__file__).parent / "deploy.py" # Get all lines with a function definition. lines = [ line for line in path.read_text().splitlines() if ' def ' in line ] breakpoint()
We set a path to the file we're trying to parse, in this case deploy.py. We then loop over all the lines in the file, keeping only the lines that have def in them.
I like to put a breakpoint at the end of the file I'm actively developing, so I can verify the existing code works, and try out ideas for the next block of code. Here we can check that lines contains only lines with function definitions:
$ python fn_checklist.py (Pdb) len(lines) 22 (Pdb) lines[0] ' def __init__(self):' (Pdb) lines[1] ' def create_parser(self, prog_name, subcommand, **kwargs):'
This looks correct. It's picked out just 22 lines from a 500-line file, and the first two items contain function definitions.
Note: If you're unfamiliar with list comprehensions, the block defining lines is equivalent to this for loop:
lines = [] for line in path.read_text().splitlines(): if ' def ' in line: lines.append(line)
Regular expressions are quite useful
Now we need to extract the function name from each line we've pulled from the file. This is exactly why regular expressions were developed. Here's an example of the kind of line we want to parse:
def create_parser(self, prog_name, ...):
We want to capture everything after def , and before the first open parenthesis. Here's a regular expression that does just that:
fn_name_re = r".*def ([a-z_]*)\("
Briefly, regular expressions are raw strings that describe patterns you're looking for. Here .*def matches any sequence of characters, followed by def, followed by a single space. We can't just match def, because it could be indented. Sometimes we're matching def , sometimes def , and sometimes even deeper indentation levels.
The next expression, ([a-z_]*), matches function names. The parentheses capture whatever matches this part of the expression. We want the function names, so we're capturing them when we look at each line. The element [a-z_] matches any single lowercase letter or underscore. The * that follows says to match all the lowercase letters and underscores that are found. The last part, \(, looks for the opening parenthesis that indicates the start of the function's argument list.
Here's a visualization showing how parts of the regular expression match up with an actual line containing a function definition:

In this example .*def matches "def ", ([a-z]*) matches "create_parser", and \( matches "\(". The rest of the string is ignored. Only "create_parser" is captured, which means we can retrieve it for use in the rest of the program.
I tend to write regular expressions like this by hand. You can paste the string you're examining into a tool like pythex.org, and then develop a regular expression that matches exactly what you want:
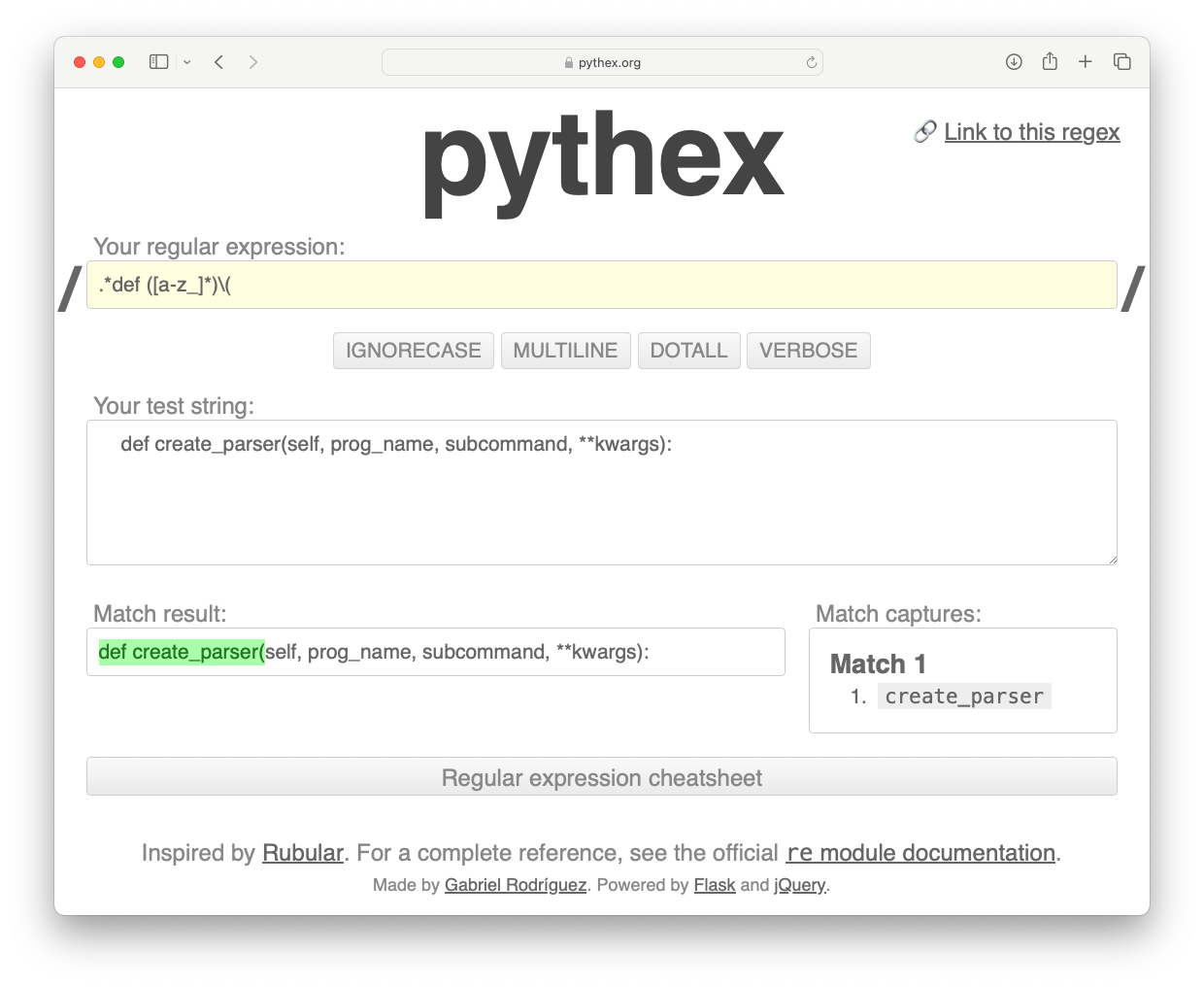
If you're interested in trying it out, here's the pythex session shown in the screenshot above. Many AI assistants will give you a reasonable start at generating a regular expression as well, or help you adjust one that almost works for your use case.
Extracting all function names
Now we can use this expression to pull out a list of function names from the file we're examining:
from pathlib import Path import re ... # Extract each function name. fn_name_re = r".*def ([a-z_]*)\(" fn_names = [ re.match(fn_name_re, line).group(1) for line in lines ] breakpoint()
This is a list comprehension that calls re.match() on every line containing a function name. When a regular expression matches a string, the parts of the string that were captured are available through the group() method. Here we're working with the match at index 1, which corresponds to the ([a-z]*) part of the regular expression.
Again, if you're new to list comprehensions, this is equivalent to:
fn_names = [] for line in lines: fn_name = re.match(fn_name_re, line).group(1) fn_names.append(fn_name)
We end up with a list of function names:
$ python fn_checklist.py (Pdb) fn_names ['__init__', 'create_parser', ..., '_confirm_automate_all']
That's great! No def keywords, no parentheses, just function names.
Generating a GitHub Issues task list
Now we can take these names and use them to generate a snippet of markdown that can be pasted into a GitHub Issues comment box:
... # Generate an issues task list. for name in fn_names: task = f"- [ ] `{name}()`" print(task)
This block loops over the function names, inserting - [ ] ` before each name, and ()` after each name:
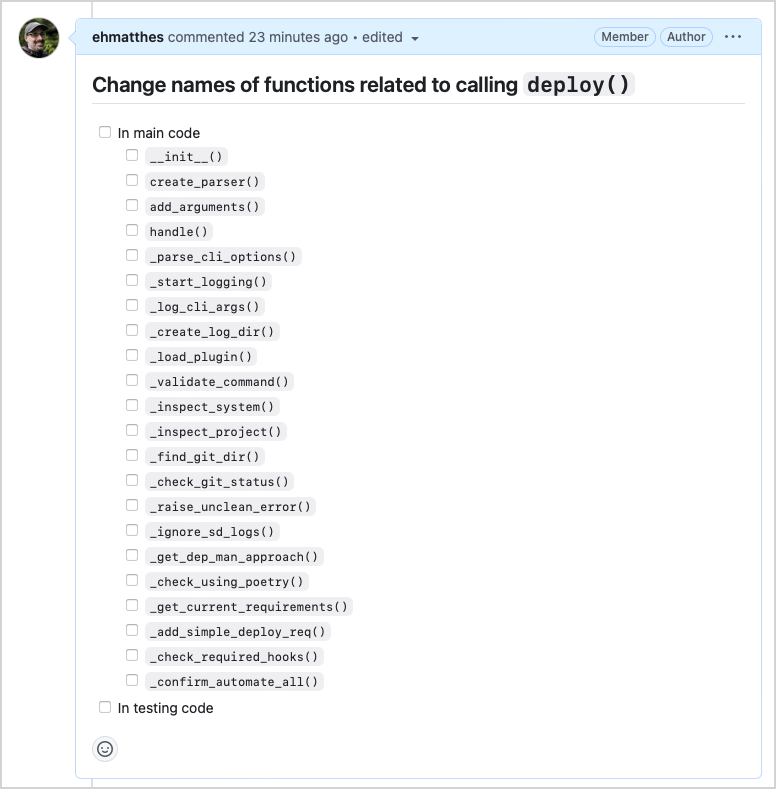
$ python fn_checklist.py - [ ] `__init__()` - [ ] `create_parser()` - [ ] ... - [ ] `_check_required_hooks()` - [ ] `_confirm_automate_all()`
Here's what the output looks like after being pasted into a GitHub Issue:
Passing the filename
This program is a lot more useful if the target file isn't hardcoded. We don't need a named argument, we'll just pull the first arg from sys.argv:
from pathlib import Path import re import sys path = Path(sys.argv[1]) # Get all lines with a function definition. lines = [ ...
The value of sys.argv is a list, with some information about how the program was called. The first item in the list is the module that's being run, and the second item is the first argument that was passed on the command line.
Here's how you can use the program now:
$ python fn_checklist.py deploy.py - [ ] `__init__()` - [ ] `create_parser()` ...
This makes the program much more flexible. Also, you can use your terminal's tab-completion to target any file on your system. This is a nice way to turn your programs into CLI utilities.
Refactoring
One of the interesting things that comes up when writing about my own code is that I often reflect the approaches I started out with, and come up with something better. When writing this post I realized I was running a regular expression over a bunch of individual lines, when I could probably run the same regular expression over the entire file at once.
That idea works, and it's a lot less code. Here's the entire final version of the program:
from pathlib import Path import re import sys # Read program file. path = Path(sys.argv[1]) contents = path.read_text() # Find all function names. fn_name_re = r".*def ([a-z_]*)\(" fn_names = re.findall(fn_name_re, contents) # Generate an issues task list. for name in fn_names: task = f"- [ ] `{name}()`" print(task)
Instead of reading in the individual lines of the file, we read the entire .py file as a single string. We then use the findall() function from the re module, which returns all occurrences of the pattern you're looking for in one list.
That's much simpler code! Maybe next time I'll remember to reach for findall() right away. :)
Conclusions
Refactoring is satisfying work, but it's a more involved process when working on larger projects and longer files. Having a system for keeping track of your progress is critical, and a task list covering all parts of a file can be helpful. It makes it easier to step away from your work and pick right back up where you left off.
Also, it makes it much easier to do your refactoring in whatever order makes sense, while keeping track of which functions you've reviewed. For example, you can review your functions by following different execution paths, rather than working your way through the file from top to bottom.
I know there are ways to improve this code, but it's worked for me on several projects. I'll clean it up further if it continues to prove useful. If I do so, I'll probably look at using Python's introspection tools from the standard library rather than parsing the .py file manually. That would support parsing of all legal function names, rather than just the names I've been using. It would also support other elements of a program, such as class names.
Resources
You can find the code from this post in the mostly_python GitHub repository.



