Automating Substack Notes
MP 43: A guest post from Charlie Guo, of Artificial Ignorance.
Note: This is the first guest post on Mostly Python, and I’m thrilled to have Charlie Guo as a guest author. Charlie writes Artificial Ignorance, my favorite source for keeping up with what’s happening in the AI world. Things are changing so quickly it’s hard to keep up with everything. Charlie does an amazing job of summarizing what’s happening each week, without becoming just another link aggregator. I appreciate someone with relevant expertise curating what I should be paying attention to, and Charlie does a fantastic job of that in the AI world. If you’re not already following his work, please take a look at what he writes.
Charlie reached out to share that he had come up with a way of automating his workflow around Substack’s Notes feature, and offered to write up his approach. I really like what he’s come up with, because what he shares here is about much more than working with Notes. Most tutorials featuring the Requests package don’t go much beyond r = requests.get(). In this post Charlie shows you how to use Request’s Session object, which is critical when working with remote resources that require authentication, but don’t have an established public API. I hope you enjoy the post, and thank you Charlie for reaching out!
Let me tell you a secret: when it comes to social media and content, I’ve pretty much always been a lurker. A consumer, not a creator.
But six months ago, that all changed. Now, I’m writing 2-3 newsletters per week, and posting on Twitter on a regular basis. It’s a huge change for me, and if I’m honest a lot of that change has been uncomfortable. I don’t have the intuition, muscle memory, or inherent social skills for this!
Luckily, there’s a silver lining: I’m running into lots of new challenges, and I get to leverage my 15 years of Python experience to solve them. Which brings us to today’s post.
As I've been getting used to posting on Twitter, I wanted to try repurposing my tweets across different platforms. And recently, Substack launched Notes, its Twitter competitor. So I decided to try and automatically cross-post my tweets to Substack Notes.
Automating Substack Notes
Now, if Substack had an API, this write-up would be pretty short. Unfortunately, Substack has no official APIs—so we'll need a more creative solution. What we can do instead is simulate a browsing session where we log in and post a Note.
At a high level, here are the steps:
- Create a browser session.
- Log in to Substack with my username and password.
- Using the same session, post a new Note.
Rather than relying on public APIs, we can use Substack's internal APIs to post the content if we're logged in. It sounds simple, but let's break down each of those steps in more detail—and write some Python examples.
Creating a browser session
When it comes to automating web browsing in Python, there are a few ways to get things done. For a long time, the de facto library was Selenium, which has methods to interact with headless browsers. It's still around, but there are some competing libraries such as Puppeteer and Playwright.
In my case, I've got a pretty simple use case, so I'm going to stick with a tool I know and love: Requests. If you're not familiar, Requests is an amazing library that makes HTTP requests “just work.” While most people use it for API calls or basic GET/POST requests, it has a lot of extra features. One of them is the Session object:
import requests
session = requests.Session()When you create a Session, Requests will keep the cookies and headers for every future request. That's a key step in our plan, since we need to be logged in from Substack's point of view to create the Note.
Logging into Substack
Next up is automating our Substack login. One important thing to note is that by default, Substack doesn't use passwords. Instead, it uses one-time auth emails to log users in. To automate your login, you'll need to go into your settings and add an account password.
From a technical perspective, we “just” need to figure out the POST data the browser is sending when we login. We can do that by logging out, opening the developer console, and inspecting the request when we log in:
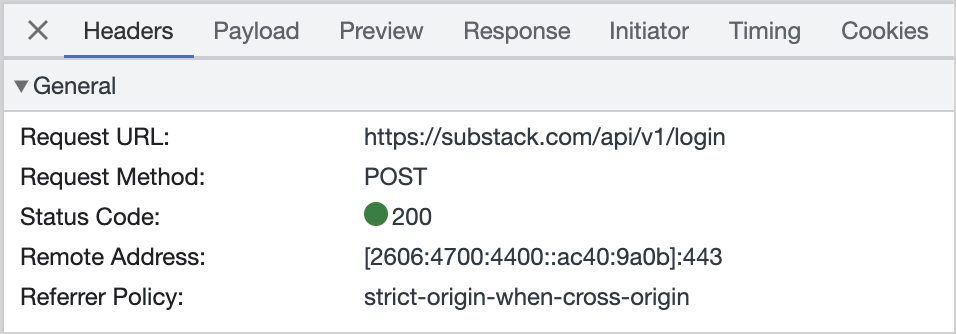
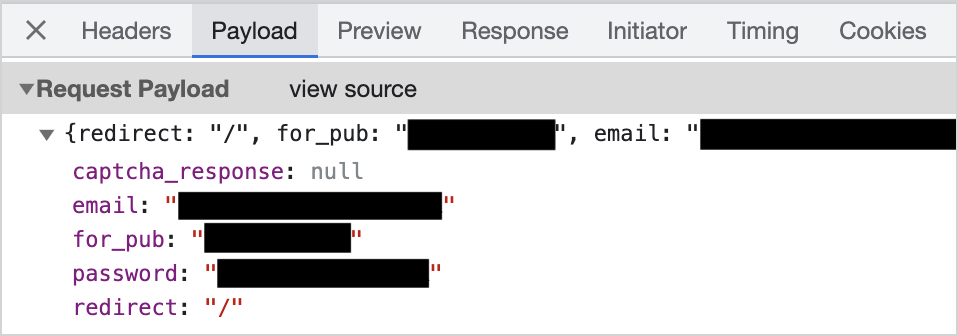
When we look at the request, we can see the target URL is https://substack.com/api/v1/login and the data sent includes our email and password. We can convert that to Python and use our session object to make a POST request:
import requests
session = requests.Session()
# Log in, using the existing session.
login_url = "https://substack.com/api/v1/login"
login_data = {
"redirect": "",
"for_pub": "PUBLICATION",
"email": "MY_EMAIL",
"password": "MY_PASSWORD",
"captcha_response": None,
}
login_response = session.post(login_url, json=login_data)We store the data needed for the login request in login_data, and include this dictionary in a call to session.post().
If we test this locally, we can see that login_response returns a 200 status code. However, in production, you'd want to be sure not to leave your email and password in plaintext.1
Posting the note
We've successfully created a session and logged into our account. The next step then, is posting our Note. But there's an issue—we don't know the data format for notes.
Luckily, we can take the same approach as our login. By opening up the developer console for Substack Notes, we can inspect the payload and response.

Notice that the data structure for a Substack Note is much more complex than the data for logging in. In the case of the Note, we are sending several pieces of metadata. And the Note itself isn't plain text, but a set of nested dictionaries which describe the different types of content.
If we wanted to get fancy with how we were creating Notes, we could reverse engineer this format. But for the sake of the prototype, we're going to focus on the basics. Given a tweet, we want to split it into paragraphs, and add the relevant metadata for our Note:
...
# Assemble data for the note.
note_url = "https://substack.com/api/v1/comment/feed"
note_headers = {"Content-Type": "application/json"}
note_content = []
for line in tweet.split("\n"):
if line:
note_content.append(
{"type": "paragraph",
"content": [{"type": "text", "text": line}]}
)
else:
note_content.append({"type": "paragraph"})
note_data = {
"bodyJson": {
"type": "doc",
"attrs": {"schemaVersion": "v1"},
"content": note_content,
},
"tabId": "for-you",
"replyMinimumRole": "everyone",
}
note_response = session.post(note_url,
headers=note_headers, json=note_data)We’re starting with a tweet represented as a single string, which means paragraphs will be indicated by newlines ("\n"). Calling the split() method with a newline character as the argument gives us a sequence of paragraphs. Each of these paragraphs is formatted in the structure that Substack’s Notes backend requires.
When all of the information is ready, we make another call to session.post().
Putting it all together
We have all the pieces, now we just need to combine them. Here's the final code:
import os
import requests
def post_note(tweet: str):
if not tweet:
return
# Start a session.
session = requests.Session()
# Log in to Substack.
login_url = "https://substack.com/api/v1/login"
login_data = {
"redirect": "",
"for_pub": "",
"email": os.environ.get("SUBSTACK_EMAIL"),
"password": os.environ.get("SUBSTACK_PASSWORD"),
"captcha_response": None,
}
login_response = session.post(login_url, json=login_data)
# Bail if we were unable to log in.
if login_response.status_code != 200:
raise ValueError
# Assemble data for Note.
note_url = "https://substack.com/api/v1/comment/feed"
note_headers = {
"Content-Type": "application/json",
}
note_content = []
for line in tweet.split("\n"):
if line:
note_content.append(
{"type": "paragraph", "content": [{"type": "text", "text": line}]}
)
else:
note_content.append({"type": "paragraph"})
note_data = {
"bodyJson": {
"type": "doc",
"attrs": {"schemaVersion": "v1"},
"content": note_content,
},
"tabId": "for-you",
"replyMinimumRole": "everyone",
}
# Post the Note.
note_response = session.post(note_url, headers=note_headers, json=note_data)
return note_responseNotice a few things that are different:
- The code has been bundled into a function that takes a tweet string.
- Instead of keeping our email and password in plain text, we're using
os.environ.get()to avoid leaks. Be sure to set your environment variables if you're using this code! - If the login fails, we raise a
ValueError.
But while this script will certainly work, it still requires a human to run it. What could we do to fully automate cross-posting?
There are a few approaches, but as they're not particularly Python-centric, I'll leave them for another post. My preference, though, would be a service like Zapier, which could let me connect my Twitter account to a Python function, and automatically repost my tweets to Substack Notes.
A personal note: Why I stopped being a lurker
In case you were wondering about my sudden change of heart on social media. The thing that finally got me off the sidelines was generative AI. And by the way, if you haven’t read it yet, Mostly Python has a fantastic series on grounding yourself as a programmer in the AI era.
For most of 2021-2022 I was living under a rock. And when I finally stuck my head out in early 2023, my jaw was on the floor as I saw how far generative AI had come. GPT-3, Midjourney, DALL-E, and of course ChatGPT.
I’ve been in tech for over 10 years, and writing code for over 15. I studied machine learning at Stanford. But I was shocked by what had become the state of the art. And so I started digging. And I just kept finding fascinating, incredible things.
For the first time in a really long time, I felt like a kid in a candy store with technology. I’ve seen past hype cycles: drones, VR, blockchain, 3D printing, and many, many more. None of them shook me like generative AI. I have a million thoughts about this space, and I’m trying to write them all down and organize them as fast as I can.
And yes, there is a massive amount of hype in this space. Plenty of folks are churning out the fast food equivalent of content and demos trying to make a quick buck. But I’ll still be writing about this stuff for a long while, even if it’s for an audience of one—because I can’t stop thinking about it.
Resources
You can find the code files from this post in the mostly_python GitHub repository.
You may also be interested in reading more about Request’s Session objects.
A common way to do this is to set your email and passwords as environment variables:
$ export MY_EMAIL=eric@example.com $ export MY_PASSWORD=veryverysecretThen you can pull those values into your Python code:
import os my_email = os.environ.get("MY_EMAIL") my_password = os.environ.get("MY_PASSWORD") # Use email and password in code.This way you can commit your code and push it to a repository without any credentials being stored. You can also freely share your code with colleagues without them seeing your credentials. ↩



