Amusing logical errors
MP 86: And the value of small utility functions.
Note: I was hoping to send this week’s post from Ghost. But it’s been a busy week, and I need a little more time to manage the transition off of Substack. (I don’t recommend trying to do a site migration while trying to sell your house in preparation for a 5,000-mile move.)
As programmers, we choose to spend a significant part of our lives chasing bugs. I think it’s probably fair to say we spend more time staring at code that’s broken in some way, than code that’s working exactly as it’s supposed to.
In this post I’ll share some of the work I’ve been doing to move this newsletter to Ghost, and how it relates to troubleshooting errors in the early stages of a project.
Two kinds of bugs
Broadly speaking, there are two kinds of bugs. One class of bugs causes code to break. At some point while executing the code in a project, Python encounters an error it can’t resolve effectively enough to continue running. This kind of error leads to a traceback, which hopefully has enough information to point you toward the source of the issue.
The second kind of bug is a logical error. In this case, the program is able to complete its execution. If an issue arises during the program’s execution, Python can find a way around it without generating a traceback. These bugs are often harder to sort out. They usually depend on a deeper understanding of the problem you’re trying to solve, and a detailed understanding of how the code addresses that problem.
Back to code blocks
Early last year I wrote a long post about how Substack should improve their code blocks if they want to support good technical writing. They haven’t done anything to address this, and one of the main reasons I’m moving off of Substack is that it’s not designed well for technical writing.
As an example, here’s a block of code I want to use in an upcoming post:
from pathlib import Path
path = Path("coffees.txt")
contents = path.read_text()
print(contents)This is about as much as you can do with a code block on Substack. There’s no syntax highlighting, and there’s no built-in way to indicate which lines you’re focusing on in the text. Most of us would never put up with this kind of limitation in a text editor or IDE. The lack of modern styling also limits how clearly you can talk about specific lines of code.
With its default settings, Ghost doesn’t do much better in email posts:

There are two things Ghost does better out of the box. First, you can add captions to code blocks, which makes it easier to show which file a listing refers to.
Second, Ghost lets you do more with the web version of each post. For example, you can apply syntax highlighting to the online versions of all posts:
This comes from a recognition that almost all browsers today can render the styles necessary for syntax highlighting.
Bringing styled code blocks to email posts
If possible, I’d like to render the code blocks in email posts as effectively as they’re rendered in the browser. Because Ghost is open source, it should be possible to customize emails enough to achieve this.
Like many open projects, Ghost has an API. Once a post is drafted, you can manipulate it programmatically through the API. Over the past week, I’ve been working on a script that does the following:
- Retrieve a draft post from my instance of Ghost;
- Convert every code block to an HTML block;
- Parse the contents of each code block, and apply inline styles using Pygments;
- Push a copy of the modified post back to my instance of Ghost.
It’s a bit more complicated than that, and if it ends up working I’ll write a post that covers the entire process in detail. But so far, it seems to be working. Here’s the same code block shown earlier, after being run through this extra processing:

This is a screenshot of a test email sent from Ghost. The email contains an actual code block, not an image of highlighted code. You can copy the code straight from the code block, and paste it into an editor. I believe screen readers can parse the code as well as they parse any code listing online.
Some newsletter writers are embedding images of code blocks in their emails to achieve this same effect. But that approach requires clicking a link to an external site if you want to work with the actual code. The image-based approach is also much less accessible, as screen readers can’t parse the actual code. You can’t enlarge the text or do any other manipulation that depends on access to raw text content.
Taking it one step further: Highlighting lines
One of the most important things to communicate in a technical post is how code changes as you progress from a simple example to a more complex, fully implemented program. On Substack, you have to rely on something like bold text for that.
What most writers want to do is highlight the lines that have changed in a listing. I’m trying to add one more feature to the Ghost processing script. It will examine the first line in each listing, looking for a directive such as hl-lines=[1, 3, 5,6,7]. If it finds a directive like this, it will insert additional styling to highlight these lines.
I almost have this working. One of the challenges is that code blocks look something like this when represented as strings:
from pathlib import Path\n\npath = Path("coffees.txt")After being run through a highlighter like Pygments, they look more like this:
<span...>from</span> <span...>pathlib</span><span...>import</span>
Path\n\npath <span...>=</span> Path(<span...>"coffees.txt"</span>Basically, every element that needs to be styled is wrapped in <span></span> tags.
To highlight individual lines, you need to insert new tags at some of the line breaks. But syntax highlighters that don’t deal with lines as individual units don’t care where newline characters end up. After running text through a highlighter, you end up with line breaks in the middle of sections that have consistent styling:
<span...>import</span> Path\n\npath <span...>...At one point I was trying to parse this kind of text. I needed to preserve the styling that Pygments had generated, and add my own style to highlight some lines. Here’s what I saw when I ran the parser:
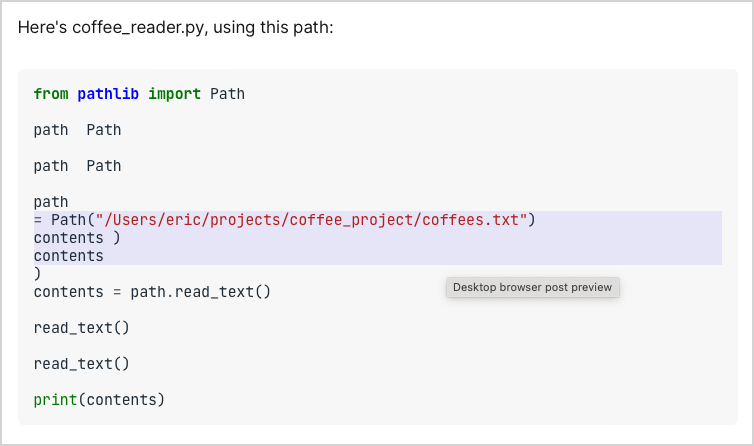
That’s a lot of paths! And a lot of read_text() calls as well. :)
There are a number of things to notice here. First of all, as a programmer, I’ve always been amused to see output like this. I imagine many non-programmers think we just write some code and it either works or doesn’t work. I don’t think most people realize we see half-broken output like this on a regular basis.
This kind of output is also a little deflating, because as programmers I think we tend to be optimists. Whenever we run a program, we hope to see correct output. Seeing incorrect output is a bit of a letdown, because it means we’re not done yet.
But there are glimmers of hope in the output shown here. Some lines are highlighted, and the highlighted section contains some of the code I wanted to see highlighted. Also, there seems to be a pattern in the incorrect output. All the content we want to see is there, but some of it is repeated. There’s almost certainly a systematic mistake I’m making, that once corrected will generate the correct output.
The value of utility functions
I haven’t implemented a fix quite yet, but I have a good idea about what to try next. My problem arose in part because Beautiful Soup manages elements of a web page as a tree, made of nodes called tags. Some of the newline characters were embedded within a single tag, and I tried to split those tags up into several independent parts. I tried making copies of the tags and then adjusting the strings associated with each one. However, the new tags all pointed at the same string attribute that the original tag had. Changing the content of any one tag changed the content of the original tag, and all the new tags that had been created as well. That’s where the repetition in the rendered code block came from.
My post parser is a new project, and right now it’s a big mess of parts that mostly works. Rather than continuing to try to troubleshoot this issue within the context of the whole project, I’m going to pull the tag-splitting work out into a separate utility function. The function will take in a tag with embedded newlines, and return a sequence of tags with the newline characters isolated in individual tags. I’ll write a test for the new function, and then call the new function from the main project. This is the kind of work I was planning to do later, but doing it now will make my life a little easier today, and save future me some refactoring work.
If you can isolate problematic code, it’s almost always easier to troubleshoot, easier to use in a larger project, and easier to maintain as you run into more edge cases.
Conclusions
Most code blocks in emails look about the same as they did in the early 2000s. Hashnode is one of the first platforms I’ve seen that has rejected the idea that emails can’t contain nicely styled code blocks, and I appreciate their work in this area. Modern code blocks are more visually appealing, but more importantly they support clear communication about technical topics.1
I’m hoping to send next week’s newsletter out from Ghost, and it should have much better code blocks than what you’ve been seeing previously on Mostly Python. If you see better code blocks in the next few posts, you’ll have a good idea of what kind of work has gone into making them possible. :)
Note: When the first post goes out from Ghost, I’m still planning to send a final post from Substack shortly afterwards to let people know it’s been sent, and how to reach out if you can’t find it.
I briefly considered using Hashnode, but they seem to be targeting developer blogs at companies. I know some individuals are using them, but I don’t think that’s the primary use case for Hashnode. It’s also not an open platform, and I don’t want to have to deal with another migration if they take their platform in a different direction at some point. ↩



