Django from first principles, part 11

MP 103: Generating sample data for local development.
Note: This is the eleventh post in a series about building a full Django project, starting with a single file. This series will be free to everyone, as soon as each post comes out.
The BlogMaker Lite project is coming along nicely, but there's very little data in the project. That's understandable, because we don't want to write a bunch of blog posts just to see what the project might look like under real-world usage. Fortunately, there's an efficient way to generate arbitrary amounts of sample data for a project like this.
In this post we'll use a library called Factory Boy, and the underlying library Faker, to generate sample blogs and blog posts. This will let us see what the project might look like under real-world usage, and make sure everything works well with full-length blog posts. We'll also be able to refine the layout as needed, based on what we see.
Generating sample data
We're going to generate sample data for the project, but we want to do it in a way where we can recreate the sample data any time we want. We basically want to be able to delete all existing data from the database, and repopulate it with fresh sample data at any point. We'll do this by writing a script that carries out these steps for us.
Flushing the database
I assume you've been entering some data into your project to make sure it works. Hopefully none of that data is important. Sometimes, especially during local development work, you'll want to empty your database while preserving its structure. Only take the following steps if you're willing to erase the data you've already entered into your project.
The Django management command flush empties all data from your project, without affecting the structure of the database at all. You can run it manually on the command line:
$ python manage.py flush You have requested a flush of the database. This will IRREVERSIBLY DESTROY all data... and return each table to an empty state. Are you sure you want to do this? Type 'yes' to continue, or 'no' to cancel: yes
If you run this command and then go to the All blogs page, you'll see the message No blogs have been added yet:
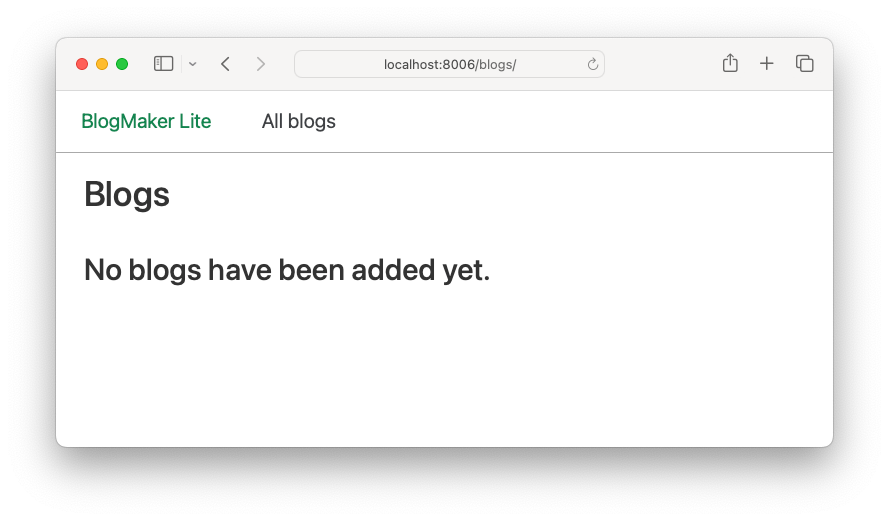
flush, the database is empty.When we generate sample data, we'll want to start with an empty database. We don't want to have to run flush manually every time we generate sample data, so let's start by calling this command from a script.
Flushing from a script
The script we're going to write is called generate_sample_data.py. Here's the first part, which runs the flush command:
"""Script to generate sample data.""" import os import django from django.core.management import call_command # Load settings. os.environ["DJANGO_SETTINGS_MODULE"] = "settings" django.setup() # Flush current data. call_command("flush", "--noinput") print("Flushed existing db.")
When you're developing a Django project, you typically interact with the project through a browser. When you start the development server by calling runserver, it does some setup work including loading settings, and inspecting the project. When you run a .py file directly in a Django project, you need to do that setup work explicitly. Here we're setting an environment variable called DJANGO_SETTINGS_MODULE, which tells Django that our settings are in the module settings.py, at the root level of the project. We then call django.setup() as well.
The call_command() function lets you run management commands from within a script. Here we're calling flush, along with the --noinput flag. This runs the flush command without prompting for confirmation.
Running this script clears out the database, while preserving its structure:
$ python generate_sample_data.py Flushed existing db.
Now we can move on to generating sample data.
Creating a superuser
Flushing the database gets rid of all data in the project, including any user accounts you've created. We want to be able to access the admin site after generating sample data, so we need to create a new superuser.
Earlier in the series, we created a superuser by running createsuperuser, which starts an interactive session that prompts for the information needed to create an admin account. You can pass some flags to createsuperuser so that it creates an admin account without any interaction. Here's an example of this version of the command:
$ export DJANGO_SUPERUSER_PASSWORD=fake_pw $ python manage.py createsuperuser --username fake_admin --email fake_email@example.com --noinput Superuser created successfully.
Passwords are sensitive information, so Django will only read a superuser password from an environment variable. Here we set the DJANGO_SUPERUSER_PASSWORD environment variable, so Django can read it when we run createsuperuser. When we run that command, we pass the --username and --email flags, as well as the --noinput flag. (Note that on Windows you'll need to use set instead of export when setting the value of DJANGO_SUPERUSER_PASSWORD.)
If you run this command, you should be able to log into the admin site with the username fake_admin, and the password fake_pw:
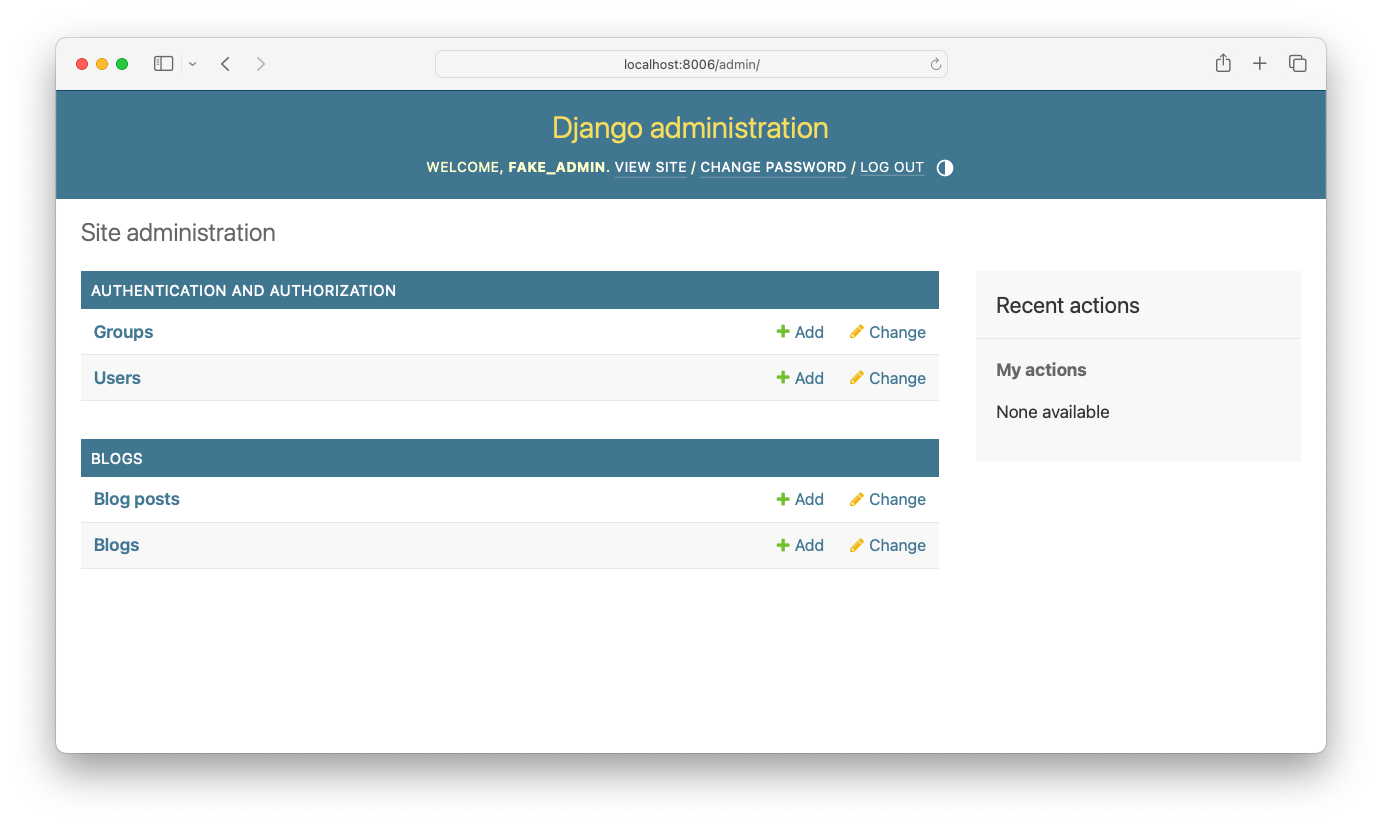
fake_admin user account.Instead of having to run this command manually, let's add it to our script:
... # Create a superuser. os.environ["DJANGO_SUPERUSER_PASSWORD"] = "fake_pw" cmd = "createsuperuser --username fake_admin" cmd += " --email fake_email@example.com" cmd += " --noinput" cmd_parts = cmd.split() call_command(*cmd_parts)
In scripts like this I like to be able to see the entire command as I'd enter it in a terminal. Here we write the command as a single string, cmd. The function call_command() doesn't take a string, though. It requires a sequence of parts that make up a command. To generate this sequence we call cmd.split(), which splits cmd wherever there's a space in the command. The * in the *cmd_parts argument "explodes" that sequence into individual parts, which are passed to the call_command() function.
If you run generate_sample_data.py you should see a message that the database was flushed, followed by a message that the superuser was successfully created:
$ python generate_sample_data.py Flushed existing db. Superuser created successfully.
You should be able to log into the admin site using the fake_admin account after running this script, and you should be able to run the script repeatedly with the same results.
Generating fake blogs
Now we're ready to generate some sample data. We'll start by generating a number of fake blogs.
First, install the library factory_boy in an active virtual environment:
(.venv)$ pip install factory_boy ... Successfully installed Faker-25.9.1 factory_boy-3.3.0...
Notice that this command installs factory_boy, as well as Faker. We'll use both of these libraries to generate sample data.
The BlogFactory class
We're going to create a factory, a class for manufacturing sample data. We'll put this in a separate file called model_factories.py, so it doesn't clutter up generate_sample_data.py:
import factory from faker import Faker from blogs.models import Blog, BlogPost class BlogFactory(factory.django.DjangoModelFactory): class Meta: model = Blog title = "My Sample Blog" description = "This is a great sample blog!"
The BlogFactory class inherits from a factory_boy class called DjangoModelFactory. This class handles much of the work involved in saving sample data to the database. It needs a Meta class that provides the model we want to generate sample data for; in this case that's the Blog model from blogs/models.py.
The factory class needs to know what data to use when creating sample blogs. For now, we'll use the title My sample blog, and a matching description.
With this factory defined, we can go back to generate_sample_data.py and make some sample blogs:
... # Create sample blogs. from model_factories import BlogFactory for _ in range(10): BlogFactory.create()
In Python, we typically put all import statements at the top of the file. But BlogFactory imports Blog, and you have to call django.setup() before importing any models. So, we import BlogFactory just before we need to use it. If you put this import statement at the top of the file, you'll get an error that's difficult to troubleshoot.
We set up a loop that runs ten times, and call BlogFactory.create(). This generates ten sample blogs, which you can see if you run generate_sample_data.py and then refresh the All blogs page:
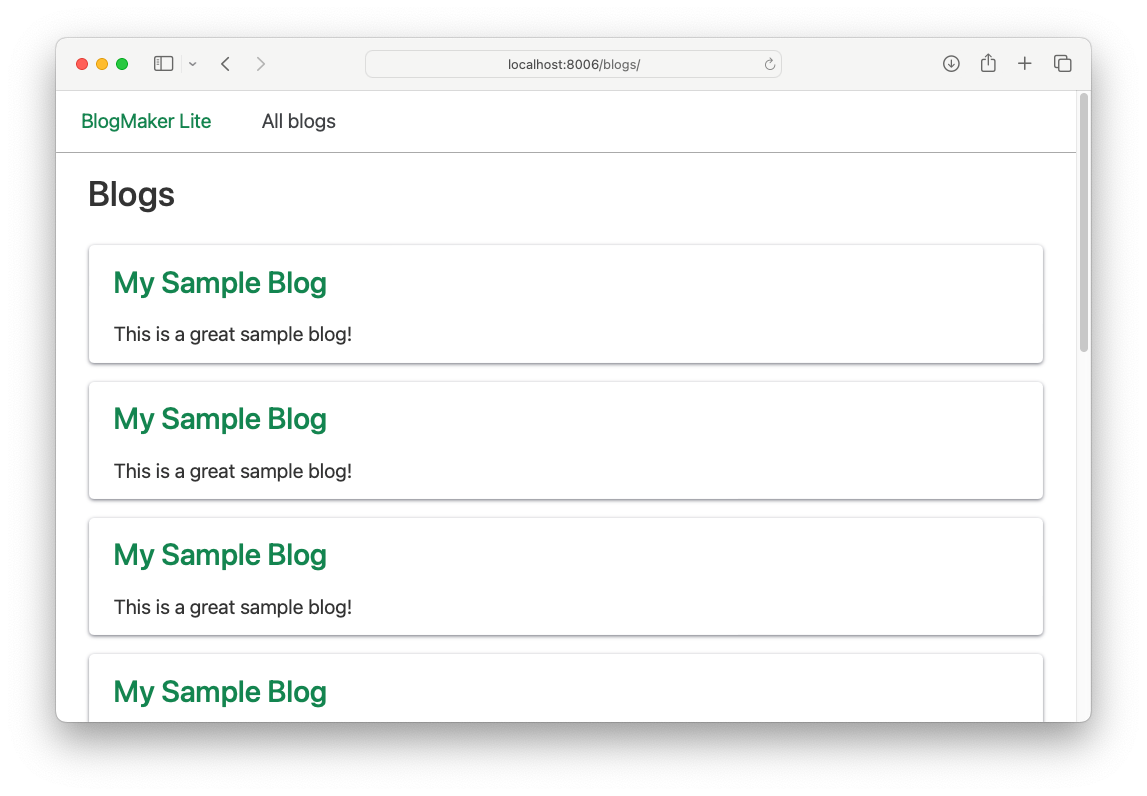
This is a good start; just by running a single .py file, we have ten sample blogs. They're all identical, which isn't very realistic. But we'll take care of that in a moment.
Generating fake data
Before trying to generate fake data in a script, let's explore the Faker library in a terminal session:
$ python >>> from faker import Faker >>> fake = Faker() >>> fake.word() 'over' >>> fake.words() ['spring', 'various', 'spend'] >>> fake.sentence() 'Practice allow treatment lawyer.' >>> fake.sentence(nb_words=20) 'Alone cost artist young whole cause partner candidate popular moment cover need.'
We import the Faker class, and make an instance called fake. We then call word(), which generates a single random word. The words() method generates a sequence of words, and sentence() returns a sentence made up of random words.
Most Faker methods have arguments that let you control how much data is generated. For example, the nb_words argument can be used to control how long sample sentences are. The default behavior is to generate a sentence with the specified number of words, plus or minus 40%. This lets you control the approximate length of sentences, without every sentence having exactly the same length.
There are quite a number of specific methods for generating sample data, such as name(), address(), and job(). Each of these comes from a provider that supplies a topical set of methods. Check out the community providers for even more kinds of data you can generate. For our purposes, we should be able to just work with word() and sentence().
Generating fake blog titles
Here's a first attempt at making a set of sample blogs, all with different titles:
... from blogs.models import Blog, BlogPost fake = Faker() class BlogFactory(factory.django.DjangoModelFactory): class Meta: model = Blog title = " ".join(fake.words()).title() description = "This is a great sample blog!"
Instead of a hard-coded title, we use Faker to generate a title made up of three words, joined by spaces, capitalized using the title() method.
This works, except all the blog titles are the same:
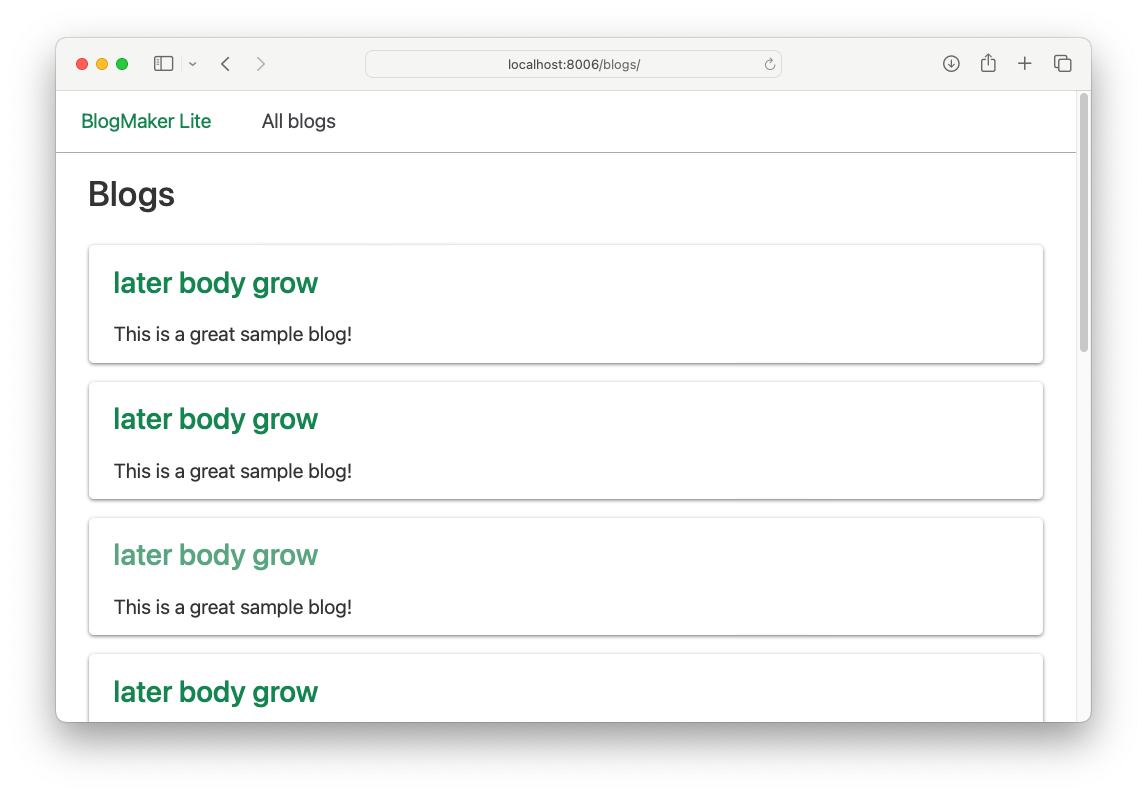
If you run generate_sample_data.py multiple times, you'll get a different title each time. But all the blogs on any given run will still have the same name.
This happens because even though we're creating a new instance of BlogFactory on every pass through the loop, Python is only evaluating the code in the class once, when the class is first loaded. Normally this makes Python more efficient, but in this case it doesn't generate the results we want.
Lazy evaluation
The solution to this is lazy evaluation. Instead of evaluating the code in BlogPost.create() once when the class is loaded, we want Python to wait and evaluate that code when it's actually called. The name is a little misleading, because Python is doing more work by running the code in create() ten times instead of once. The reference to "lazy" comes from the fact that Factory Boy puts off running that code as long as it can, and only runs it when it needs to.
Here are the modifications to model_factories.py that generate a different title for each new blog:
... fake = Faker() def get_title(): return " ".join(fake.words()).title() class BlogFactory(factory.django.DjangoModelFactory): class Meta: model = Blog title = factory.LazyFunction(get_title) description = "This is a great sample blog!"
We define a function, get_title(), that doesn't take any arguments. It uses Faker to generate a short title, converts it to title case, and returns that value.
In BlogFactory, the title field is now filled by a call to factory.LazyFunction(). This function is written so that it's evaluated every time create() is called. It takes the name of a function that should be called to get the value for the title field. 1
The result is a different title for each blog:
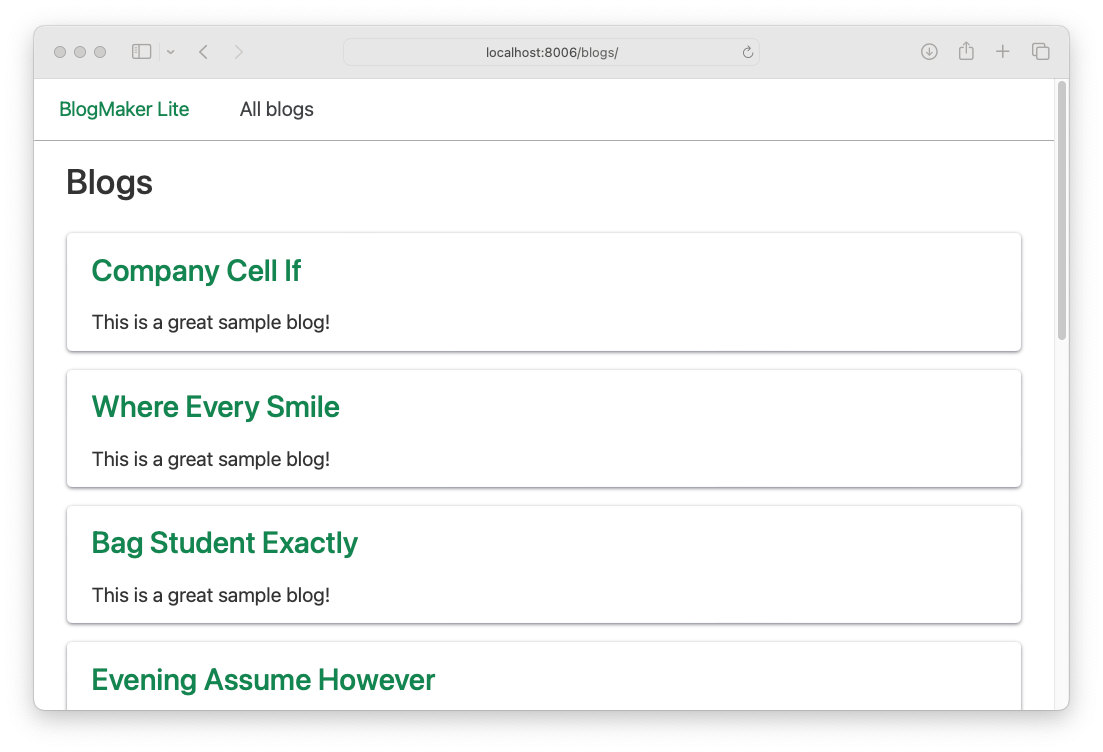
Now we can do the same thing for the description:
... def get_title(): ... def get_description(): return fake.sentence(nb_words=10) class BlogFactory(factory.django.DjangoModelFactory): class Meta: model = Blog title = factory.LazyFunction(get_title) description = factory.LazyFunction(get_description)
If you run generate_sample_data.py again, you should see different titles and descriptions for every blog.
Generating fake posts
Let's close out by generating some fake posts for each of these blogs. Here's the code in model_factories.py that generates a fake blog post:
from random import randint ... def get_description(): ... def get_body(): paragraphs = [ fake.paragraph(randint(5,10)) for _ in range(randint(3,25)) ] return "\n\n".join(paragraphs) class BlogFactory(factory.django.DjangoModelFactory): ... class BlogPostFactory(factory.django.DjangoModelFactory): class Meta: model = BlogPost title = factory.LazyFunction(get_title) body = factory.LazyFunction(get_body) blog = factory.Iterator(Blog.objects.all())
Faker has a paragraphs() method that generates a sequence of paragraphs, but I haven't had much luck generating paragraphs with any real variety in length. However, we can write a few lines of code that generates a more realistic sequence of paragraphs. The get_body() function here builds a list of paragraphs, each of which has 5 to 10 sentences. Every post will have 3 to 25 paragraphs. If you make enough posts, this generates some realistically short posts, and some realistically long posts as well.
This brings up one of the reasons I prefer using regular functions to generate sample data like this over lambda functions. Right now, get_body() is just five lines of code. If you find this sample data useful, but would like to see some really long posts with 100 paragraphs, you could add a block that adds a bunch of paragraphs to just a few posts. That's much harder to do if you're writing lambda functions for all your sample data generation.
The BlogPostFactory class is quite similar to BlogFactory, except for the blog field. This field is a foreign key to a Blog instance. The factory.Iterator() function takes a queryset as an argument, and cycles through each item in the queryset as needed. Here we pass all the Blog objects to factory.Iterator(). This distributes sample blog posts evenly among all the blogs that were created earlier. 2
Here's the changes needed in generate_sample_data.py:
... # Create sample blogs. from model_factories import BlogFactory, BlogPostFactory for _ in range(10): BlogFactory.create() for _ in range(100): BlogPostFactory.create()
I want blogs to have multiple posts, so here I'm creating ten times as many posts as blogs.
Now you can click on All blogs, click on any of the blogs, and see all the posts that were created:
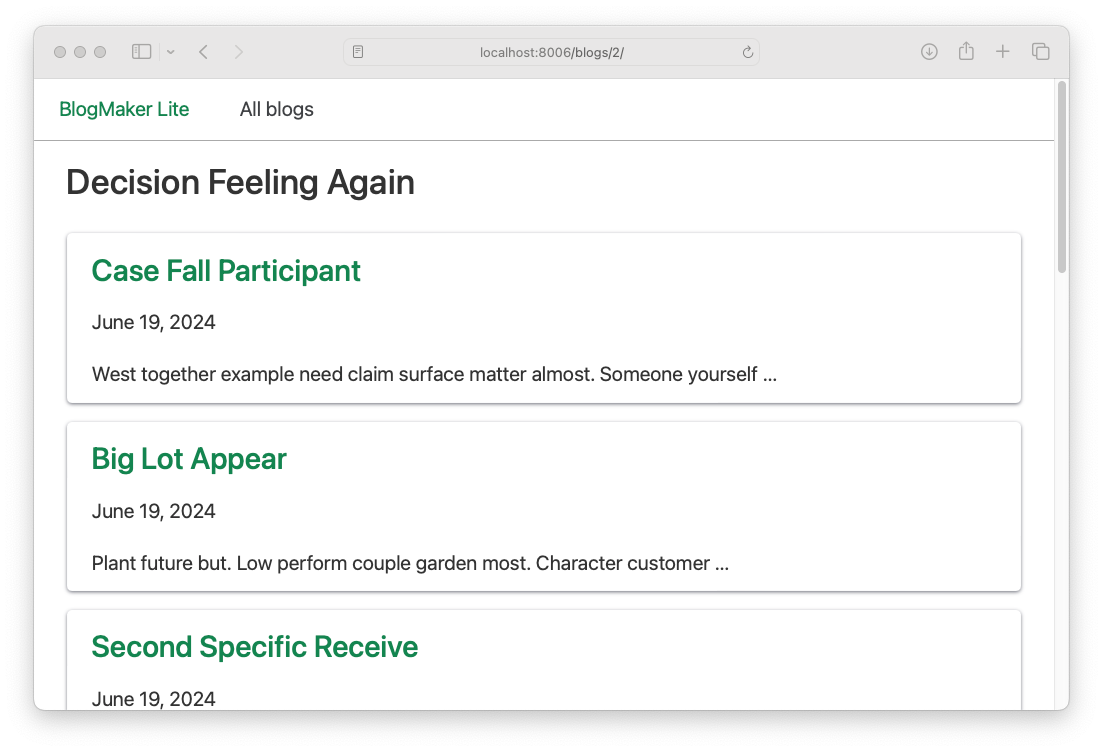
If you click on a post, you'll see the text that was generated for that post:
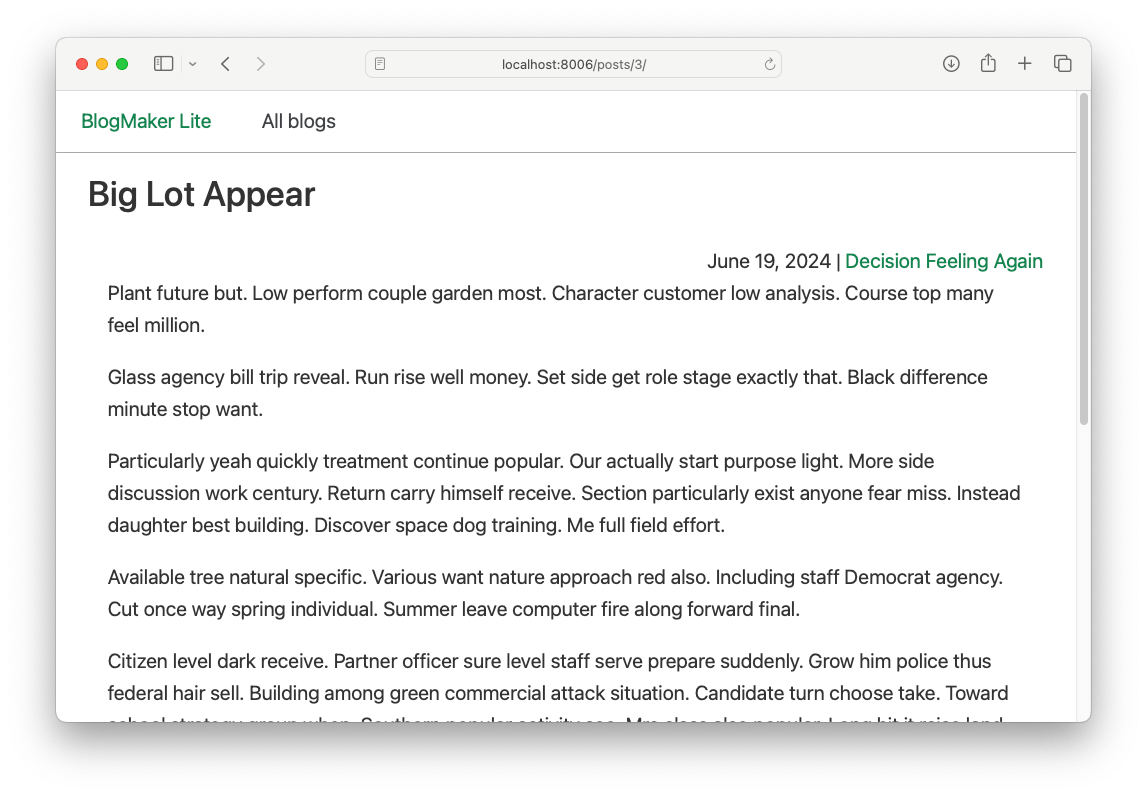
If you click through a number of sample posts, you'll find a variety of short posts, medium-length posts, and some longer posts as well.
Conclusions
I really like how a relatively short script like generate_sample_data.py can create a realistic dataset for a project like BlogMaker Lite. Developing a new Django project can feel awkward because you don't have any users yet; it can feel like working in an empty world. Generating realistic sample data can make it feel like you're working in an inhabited world, and it can give you a much better sense of what your project will look like to actual users. It can help point out some layout and functionality issues as well.
If you don't like how the project looks with the default word choices that Faker and Factory Boy use, you can configure the project to use text like Lorem Ipsum. To implement this, look at the ext_word_list argument in the documentation for Faker's methods. You also might want to consider adding a couple CLI arguments to the generate_sample_data.py script using argparse, so you can generate different amounts of data. For example you can add a parameter to specify how many blogs to create, and how many posts to create as well.
Faker has always been efficient enough for my use cases. For example, it takes about half a second to generate 10 blogs and 100 blog posts. If you're trying to make a much higher number of objects, it can take a lot longer to generate sample data. The Mimesis library offers much of the same functionality as Faker, but it runs much more quickly. However, keep in mind that the time it takes to generate sample data in a Django project depends on the library being used to generate the data, and the way the database is configured. To generate large amounts of sample data efficiently, you need to use an efficient library for generating data and configure the database in specific ways. 3
For now, using Factory Boy and Faker along with Django's default database settings should let you fill your projects with enough sample data to let you see how things will look to actual users. In the next post we'll start to transition to a focus on setting up user accounts, so people can actually create blogs and write posts. Having realistic sample data will give us more confidence that we're setting up user-focused features correctly.
Resources
You can find the code files from this post in the django-first-principles GitHub repository. The commits from this post are on the part_11 branch. Commits for this branch start at 05ff81, with the message Flushes db from script.
Often times lambda functions are used with LazyFunction(). For example here's a lambda function that generates the blog title:
class BlogFactory(factory.django.DjangoModelFactory): class Meta: model = Blog title = factory.LazyFunction( lambda: " ".join(fake.words()).title() ) description = "This is a great sample blog!"
A lot of people who have an otherwise reasonable understanding of Python are thrown off by lambda functions, so I try to omit them if possible when writing for a wide audience. You can use lambda functions with Factory Boy, but you can also do the same work with regular functions.
I like to think of a function as a named block of code. I like to think of a lambda function as a block of code so short, it doesn't need a name. Here the argument for LazyFunction() is a rule for generating titles. All lambda really means in this situation is, "Here's a rule to use when it comes time to generate a title."
As a Python programmer, it's certainly a good idea to try to understand lambda functions. They're not as difficult as they're often made out to be. But if you're not comfortable with them yet, and don't want to deal with them, you can use Factory Boy without them.
This has the drawback of creating an unrealistic dataset where every blog has exactly the same number of posts. If you want a more random distribution, you can write a function called get_blog() that chooses a random item from the queryset and returns that to the blog field, using LazyFunction().
If you're curious about tuning SQLite, see Optimal SQLite settings for Django by Giovanni Collazo. Most of that advice requires Django 5.1, which is currently in alpha. For configuration settings you can use with current Django releases, see Django SQLite Production Config, by Anže.



