Archiving real estate images

MP 124: It should be simple to do, right?
We're in the process of buying a house at the moment, and we want to keep a copy of the pictures on Zillow that show how the house is currently set up. Lots of people want to do this, and lots of people end up right-clicking each picture, one at a time, and saving them to their Downloads directory.
I'm going to try to automate this, and document the process. I'm curious how straightforward it is, and if you can do it with just a simple library like httpx, or if it requires a browser driver like Selenium. I'm also curious to see if anything surprising comes up.
Getting started
There are a number of tools out there for automating this process, but most of them seem to be browser extensions or web apps. I want to write a standalone program that does it.
I'm going to work with a Zillow listing that's already been shared widely, so I'm not calling attention to the house we're buying, or any other smaller listing. I'll start by looking up the most expensive listings on Zillow, which should turn up some widely-shared listings. A quick search for "most expensive Zillow listings New York City" turns up a $105m penthouse on Park Avenue. Perfect! Let's try to automatically download the first picture.

A naive approach
I doubt this will work, but let's try using httpx to grab the main page for the listing, and see what we get:
from pathlib import Path import httpx url = "https://www.zillow.com/homedetails/" url += "432-Park-Ave-PENTHOUSE-New-York-NY-10022/2069500049_zpid/" r = httpx.get(url) path = Path(__file__).parent / "output_file.html" path.write_text(r.text)
This writes the source HTML for the main listing page to output_file.html. We can then examine that file without having to use a browser inspector, and see exactly what gets retrieved.
If you open this file in a browser, here's what you'll see:

This is not unusual when you're trying to write a web scraper. If a site doesn't want to be scraped, there are all kinds of ways they can make it more difficult to automate usage. This is a clear sign you shouldn't be building any kind of automated scraping service. If I was trying to build a project on top of Zillow, I'd consider stopping here. For personal use to download a few images for a property I'm in the process of buying, I'll try a different approach.
Selenium to the rescue
Selenium is often able to bypass this kind of attempt to block automation, because it launches a browser which it then drives. Let's try loading the main page using Selenium.
If you haven't used Selenium before, install these two packages:
(.venv)$ uv pip install selenium (.venv)$ uv pip install webdriver_manager
This installs Selenium, and a package that makes it easier to set up a driver.
Now we can use Selenium to open a browser at the main listing:
from pathlib import Path import httpx from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager url = "https://www.zillow.com/homedetails/" url += "432-Park-Ave-PENTHOUSE-New-York-NY-10022/2069500049_zpid/" driver = webdriver.Chrome( service=Service(ChromeDriverManager().install())) # Open main property page. driver.get(url) breakpoint()
We make a driver for the browser, and ask the driver to get the same URL we tried to retrieve earlier. The breakpoint() is included so the automated browser stays open once the program finishes running.
If you run this program, you should see a new Chrome window open, with the listing showing:
Clicking an image
Now that we have the main page open, we want to click on the first image in the listing. To do this, we need to tell Selenium which element to locate on the page, and then have it click that element. This is where it's helpful to have the breakpoint() set. We can open Chrome's inspector, and look at the HTML for the first image in the set:
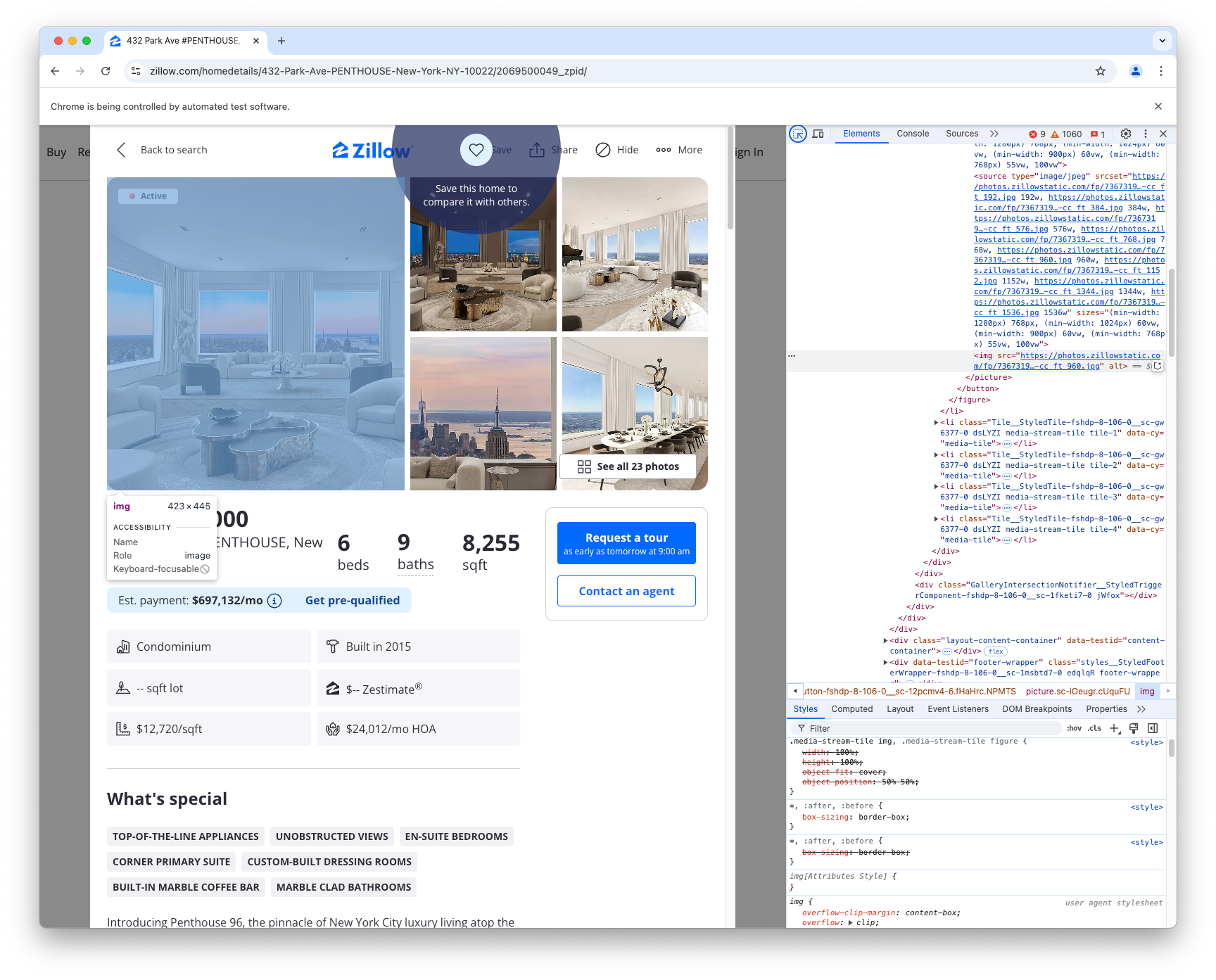
The element that gets highlighted is an <img> tag. You don't really click on an image; there's usually code around an image that makes it act as a link.
I noticed the <img> tag was nested inside a <div> tag, which also contained a <button> element. To be perfectly transparent, this is where I make regular use of AI assistants now. I understand how Selenium works; you pick an element you want to target, and write code that finds that element and then interacts with it. Rather than writing this code from scratch, I've found it much faster to give a large block of HTML to an AI assistant, and ask it if there's an element in that block I can click on.
Here's what I came up with, using a slight modification of what the AI assistant suggested:
... from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC url = "https://www.zillow.com/homedetails/" url += "432-Park-Ave-PENTHOUSE-New-York-NY-10022/2069500049_zpid/" driver = webdriver.Chrome( service=Service(ChromeDriverManager().install())) # Open main property page. driver.get(url) # Click on first image in listing. button = WebDriverWait(driver, 10).until( EC.element_to_be_clickable(( By.CSS_SELECTOR, "button[aria-label='view larger view of the 1 photo of this home']" )) ) button.click() breakpoint()
This block tells the driver to look for a <button> element with an aria-label that has the value view larger view of the 1 photo of this home. It waits for that element to be clickable. Afterwards, button.click() clicks on the button.
If you run this code, you should see the main page open. A moment later, you should see it automatically click through to the photos page of the listing:
I don't know at this point if the AI-suggested approach is especially good or efficient code. I would guess that someone who knows how to use Selenium well might have a better way of picking out the button from the page's HTML. But for a small solo mini-project, this approach gets me exactly where I want to be.
The next click
We need to click the first image on this page, in order to get to the page that features just a single image. Examining the source for this page, I found the block containing the first image. Here's the next bit of code to click on this image:
... # On main photos page. Click first image button. li_element = WebDriverWait(driver, 10).until( EC.presence_of_element_located(( By.CSS_SELECTOR, "li.viw-tile-0")) ) button = li_element.find_element( By.CSS_SELECTOR, "button[data-cy='loaded-photo-tile']") button.click() breakpoint()
The page showing all photos for a listing is structured as an HTML list. This block finds the <li> element associated with the first image (li.viw-tile-0), and then finds the button within that item that acts as a link to the single-photo page.
The program now opens the main listing page, clicks through to the photos page, and then clicks through to the first single-photo page:
This is great! We're almost ready to start downloading images. But first, we'll grab the number of photos from that "1 of 23" element in the top right of the first photo.
How many photos?
We need to set up a loop to click through each of the images. This is a carousel, and a loop that just keeps clicking the Next button would end up downloading images forever. We need to write a for loop that runs once for every image in the set.
Here I used Chrome's inspector to look at the HTML around the "1 of 23" element in the top right. I then gave that to an AI assistant, and asked it to find the element that has that text. Here's the next block:
... # On single photo page. Find out how many photos. carousel_counter = WebDriverWait(driver, 10).until( EC.presence_of_element_located(( By.CSS_SELECTOR, "div[class*='GalleryLightboxResponsiveImage__StyledCarouselCounter']")) ) counter_text = carousel_counter.get_attribute("innerHTML") of_index = counter_text.find("of") num_images = int(counter_text[of_index+3:]) breakpoint()
This finds a <div> element with a class containing the phrase StyledCarouselCounter. This is another example of how working with an AI assistant makes me more efficient. I know you can probably get Selenium to identify an element that has a specific class in its set of CSS classes. But figuring out how to do that from the documentation takes significantly longer than asking an assistant "Can you write a block that finds a <div> element that contains this class, but may contain other classes as well?" The caveat is that the AI's solution may be inefficient, unreliable, or incorrect. For a small project like this, if it works it's probably good enough for a first pass.
I wrote the three lines of code that parse the counter text. The page doesn't actually contain the text "1 of 23". It's broken up into three lines, "1", " of ", and "23". So you have to get all those elements through get_attribute("innerHTML") rather than just grabbing the text from the <div> element. In the debugger session that's keeping the browser window open, we can verify that this block pulls the correct number of images:
(Pdb) num_images 23
Now we can write a loop that runs through all the images, and downloads each one.
Looping over the images
Here's the loop that downloads all the images. This is a longer listing, but it mostly uses the same concepts we've been using:
from pathlib import Path from random import randint from time import sleep import re ... # Click through and download all images. for img_num in range(num_images): # On a single photo page. Find div containing image. div_element = WebDriverWait(driver, 10).until( EC.presence_of_element_located(( By.CSS_SELECTOR, "div.hdp-photo-gallery-lightbox-content")) ) # Extract image source URL. img_re = r'img src="(https://photos\.zillowstatic\.com/fp/.*?uncropped_scaled_within.*?\.jpg)' div_html = div_element.get_attribute("innerHTML") m = re.search(img_re, div_html) if m: img_url = m.groups()[0] # Get image, write image to file. r = httpx.get(img_url) path = ( Path(__file__).parent / "output_images" / f"property_image_{img_num}.jpg" ) path.write_bytes(r.content) else: print("Could not find image URL.") # Pause 1-3 seconds. wait_time = randint(1000, 3000) / 1000 sleep(wait_time) # Click to next picture. next_button = WebDriverWait(driver, 10).until( EC.element_to_be_clickable((By.CSS_SELECTOR, "li.photo-carousel-right-arrow button")) ) next_button.click() # Pause 1-3 seconds. wait_time = randint(1000, 3000) / 1000 sleep(wait_time) breakpoint()
The loop starts on the page featuring the first image. We find the <div> element containing the image. We then extract the link to the image, using a regular expression. (I don't use an AI assistant to write regular expressions. Instead, I copy the block of code I want to look through into pythex.org, and then write an expression that captures the URL.)
If we find an image URL we use httpx to grab the image, and then write it to a file using path.write_bytes().
That's great; we've downloaded the first image! When grabbing data from a website, it's often helpful to include a random pause between some actions. Here we call sleep() for 1 to 3 seconds. Then we find the right-arrow-button element, and click it. We pause again, and go back to the start of the loop.
If you run this program, it should click through and download all the images in the listing, stopping when it's reached the last page asking if you want to tour the featured home.
You should see all the images in the output_images/ directory:
$ ls output_images property_image_0.jpg property_image_14.jpg... property_image_1.jpg property_image_15.jpg... property_image_10.jpg property_image_16.jpg... ...
Conclusions
I'll admit it took me a bit longer to write this program than it would have to just manually right-click each of the images on the listing. But running this same program on the listing for the house we're buying was quite satisfying, and it impressed my kid who's currently learning all the things you can do as a programmer.
Resources
You can find the code from this post in the mostly_python GitHub repository.



